Introduction
In this lecture, we talk about how to aggregate the results from a group of predictors in order to achieve higher performance. For example, if you ask a difficult question from 1000 people and then aggregate the answer (the mean, median ... of the answers), in many cases you will get more accurate result than the answer from an expert. This technique is called Ensemble Learning. Last lecture, we discussed about Decision Tree classifier. Random Forest is also an Ensemble method: instead of training one Decision Tree classifier, a group of Decision Tree classifiers are trained, each on different random subset of data. All predictions can be aggregated by getting the most votes. For example, for a training instance, if you run Decision Tree classifier 100 times each for different random data set, you have 100 predictions; the class that receives the highest frequency amongst all class should be assigned as the predicted class for that training instance. This is how Random Forest predict a class. Although it is so simple, Random Forest is one of the most powerful Machine Learning algorithms.
Hard and Soft Voting¶
If you applies several classifier including Logistic Regression, SVM, Random Forest... on the same data set and each has an accuracy of around 80%, you may simply get better results by aggregating the predictions of each classifier and predict the class that receives the most votes. This approach is called a hard voding classifier. You may surprisingly get higher accuracy than the best classifier by ensemble learning if all classifier are independent from each other. For example, Figure below shows some classifiers (Logistic Regression, SVM, Random Forest...) are applied on the same data with two classes 0 and 1. For an instance, each classifier predict a different class. However, 90% of classifier predict the instance as class 1, so the final prediction will be class 1 with 90% accuracy.
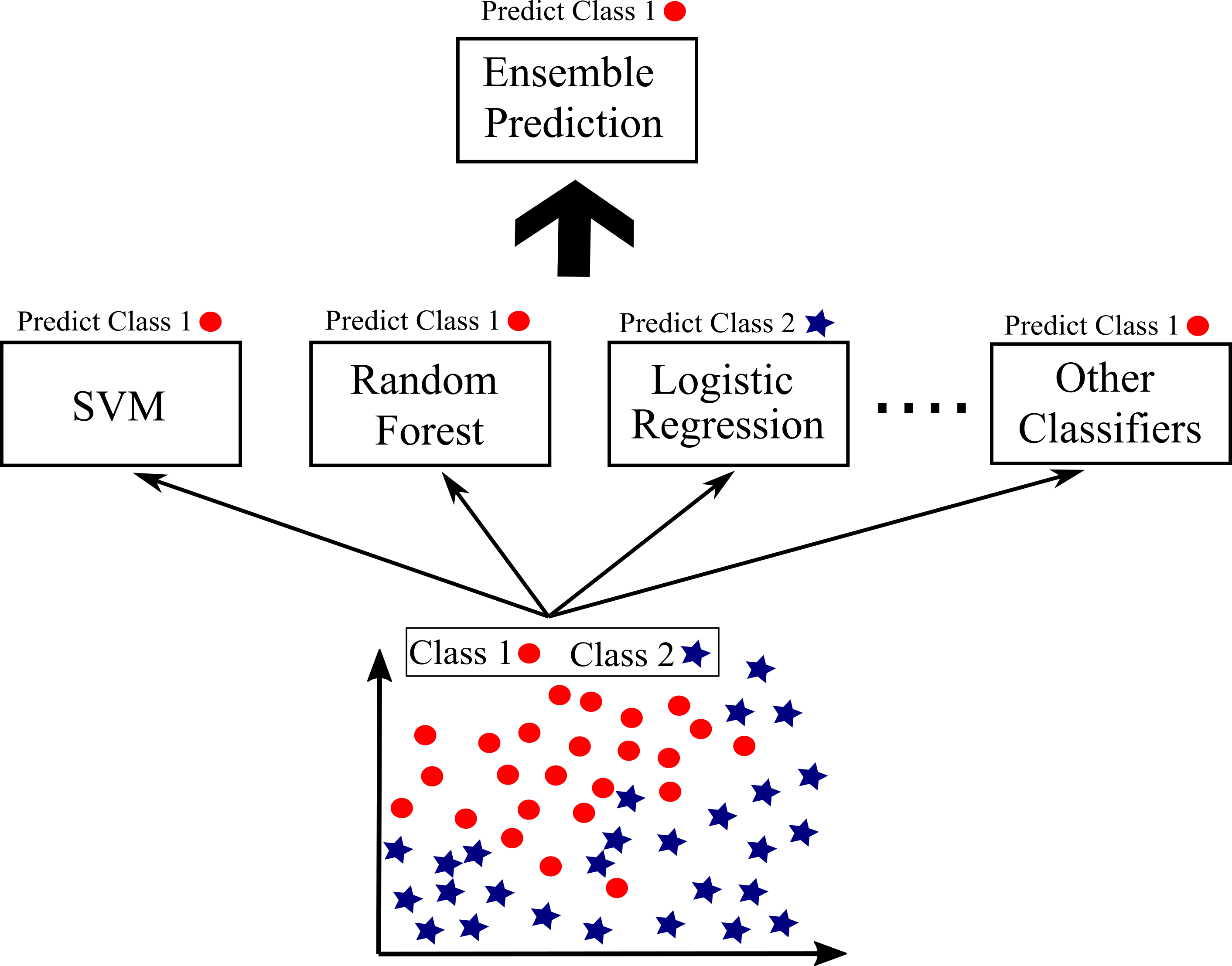
If all classifiers can predict probability of each class (dict_proba() method), Scikit-Learn can predict a class with with the highest probability by averaging over all the individual classifiers. This is called soft voting. Higher performance can be achieved by soft voting compared with hard voting due to giving higher weight to a class with highest probability.
The following code shows how to apply hard voting for Energy Efficiency data set for multiclass classification.
In [1]:
import pandas as pd
import numpy as np
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OrdinalEncoder
# Energy Efficiency Data Set
df = pd.read_csv('Building_Heating_Load.csv',na_values=['NA','?',' '])
df_multi=df.copy()
df_reg=df.copy()
df_reg.drop(['Multi-Classes','Binary Classes'], axis=1, inplace=True)
df_multi.drop(['Heating Load','Binary Classes'], axis=1, inplace=True)
ordinal_encoder = OrdinalEncoder()
Multi_Classes_encoded = ordinal_encoder.fit_transform(df_multi[['Multi-Classes']])
Multi_Classes_encoded[0:5]
df_multi['Multi-Classes']=Multi_Classes_encoded
# Shuffle
np.random.seed(32)
df_multi=df_multi.reindex(np.random.permutation(df_multi.index))
df_multi.reset_index(inplace=True, drop=True)
df_reg=df_reg.reindex(np.random.permutation(df_reg.index))
df_reg.reset_index(inplace=True, drop=True)
# Training and Test
spt = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_idx, test_idx in spt.split(df_multi, df_multi['Multi-Classes']):
train_set_strat = df_multi.loc[train_idx]
test_set_strat = df_multi.loc[test_idx]
#
train_set_strat_reg = df_reg.loc[train_idx]
test_set_strat_reg = df_reg.loc[test_idx]
# Note that drop() creates a copy and does not affect train_set_strat
X_train = train_set_strat.drop("Multi-Classes", axis=1)
y_train = train_set_strat["Multi-Classes"].values
#
X_test = test_set_strat.drop("Multi-Classes", axis=1)
y_test = test_set_strat["Multi-Classes"].values
# Note that drop() creates a copy and does not affect train_set_strat
X_train_reg = train_set_strat_reg.drop("Heating Load", axis=1)
y_train_reg = train_set_strat_reg["Heating Load"].values
#
X_test_reg = test_set_strat_reg.drop("Heating Load", axis=1)
y_test_reg = test_set_strat_reg["Heating Load"].values
# Standardization training
scaler = StandardScaler()
X_train_Std=scaler.fit_transform(X_train)
X_train_reg_Std=scaler.fit_transform(X_train_reg)
# Standardization test
X_test_Std=scaler.fit_transform(X_test)
X_test_reg_Std=scaler.fit_transform(X_test_reg)
Logistic Regression, Random Forest, SVM are applied and then the results are aggregated:
In [2]:
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
log = LogisticRegression(random_state=10)
rnd = RandomForestClassifier(random_state=10)
svm = SVC(C=10)
hard_voting = VotingClassifier(estimators=[('lr', log), ('rf', rnd), ('svc', svm)],voting='hard')
hard_voting.fit(X_train_Std, y_train)
clf=['Logistic Regression:', 'Random Forest:', 'SVM:', 'Hard Voting:']
i=0
for clfier in (log, rnd, svm, hard_voting):
clfier.fit(X_train_Std, y_train)
y_pred = clfier.predict(X_test_Std)
print(clf[i], accuracy_score(y_test, y_pred))
i+=1
As you can see, for this data set, hard voting gives a little higher performance than the individual classifiers for test set.
To apply soft voting, you need to change voting='soft' and For Support Vector Machine (SVC), you need to set its probability hyperparameter to True.
In [3]:
log = LogisticRegression(random_state=10)
rnd = RandomForestClassifier(random_state=10)
svm = SVC(C=10,probability=True)
soft_voting = VotingClassifier(estimators=[('lr', log), ('rf', rnd), ('svc', svm)],voting='soft')
soft_voting.fit(X_train_Std, y_train)
clf=['Logistic Regression:', 'Random Forest:', 'SVM:', 'Soft Voting:']
i=0
for clfier in (log, rnd, svm, soft_voting):
clfier.fit(X_train_Std, y_train)
y_pred = clfier.predict(X_test_Std)
print(clf[i], accuracy_score(y_test, y_pred))
i+=1
Soft voting works better than hard voting giving higher performance than the individual classifiers. You should always try aggregating some promising algorithms to see if the performance can be increased or not. The more diverse and independent the prediction, the higher performance should be achieved. The problem is how to get many diverse prediction??
Bootstraping¶
As we discussed, independent prediction can be achieved by using different classifiers. Another approach to get diverse prediction is to use the same training algorithm for every predictor, but training is applied on different random subsets of data. When we the sampling is applied with replacement, it is called bootstraping or bagging. When replacement is not performed, it is called pasting. Figure below shows an example of bootstraping, the same predictor (Descision Tree) is applied for many samples (say 100) from data. This leads to achieve many independent predictions. Then, ensemble learning (hard or soft voting) can be applied to aggregate the predictions.
Bagging and pasting can be applied by Scikit-Learn's BaggingClassifier class. The following code shows training of 200 Decision Tree classifiers, each trained on 100 training instances randomly sampled from the training set with replacement. Finally, BaggingClassifier automatically applies soft voting to aggregate predictions. You can apply pasting instead by just setting bootstrap=False.
In [33]:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(DecisionTreeClassifier(), n_estimators=200,
max_samples=100, bootstrap=True, n_jobs=-1)
bagging.fit(X_train_Std, y_train)
y_pred = bagging.predict(X_test_Std)
The following code show the decision boundary of a single Decision Tree on left and bootstraping ensemble of 500 trees from the code above (bagging) on the right. Both models are trained on the same data set. both trained on the moons dataset. It is clear that the ensemble’s predictions generalize (right) much better than the single Decision Tree’s predictions.
In [34]:
from matplotlib.colors import ListedColormap
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from numpy import random
from sklearn.datasets import make_moons
#
font = {'size' : 12}
plt.rc('font', **font)
fig = plt.subplots(figsize=(13.0, 4.5), dpi= 90, facecolor='w', edgecolor='k')
ax1=plt.subplot(1,2,1)
X, y = make_moons(n_samples=100, noise=0.23, random_state=10)
x1s = np.linspace(-1.8,3, 100)
x2s = np.linspace(-1.5,2, 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
np.random.seed(42)
tree_clf = DecisionTreeClassifier(max_depth=8)
tree_clf.fit(X, y)
y_pred = tree_clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['b','r'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "bs", label="Class 0")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "r^", label="Class 1")
plt.axis([-1.0, 2.0, -1.0, 1.5])
plt.xlabel(r"$X_{1}$", fontsize=18)
plt.ylabel(r"$X_{2}$", fontsize=18, rotation=0)
plt.title("Single Decision Tree \n max_depth=20", fontsize=18)
plt.legend(loc=2, fontsize=14)
ax2=plt.subplot(1,2,2)
# Decision Trees
np.random.seed(42)
bagging = BaggingClassifier(tree_clf, n_estimators=500, bootstrap=True, n_jobs=-1)
bagging.fit(X, y)
y_pred = bagging.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['b','r'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "bs", label="Class 0")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "r^", label="Class 1")
plt.axis([-1.0, 2.0, -1.0, 1.5])
plt.xlabel(r"$X_{1}$", fontsize=18)
plt.ylabel(r"$X_{2}$", fontsize=18, rotation=0)
plt.title("Bootstraping of 500 Decision Trees \n max_depth=20", fontsize=18)
plt.legend(loc=2, fontsize=14)
plt.show()

Random Forest¶
Random Forest is an ensemble of Decision Trees, so the bagging method with Decision Trees described before works the same as Random Forest. Instead of using a BaggingClassifier, Scikit learn's RandomForestClassifier class is more straightforward to apply. The following code trains a Random Forest classifier:
In [6]:
from sklearn.ensemble import RandomForestClassifier
rnd = RandomForestClassifier(n_estimators=500, max_samples=8, n_jobs=-1)
rnd.fit(X_train_Std, y_train)
y_pred = rnd.predict(X_test_Std)
Feature Importance¶
Another important application random forest is to measure the importance of each feature. A feature importance in Scikit-Learn is measured by calculating how much impurity is reduced on average by including that feature.
Lets calculate the importance of features for Energy efficiency data set.
In [35]:
from sklearn.ensemble import RandomForestClassifier
rnd = RandomForestClassifier(n_estimators=500, max_depth=8, n_jobs=-1)
rnd.fit(X_train_Std, y_train)
Out[35]:
In [36]:
Accuracies=cross_val_score(rnd,X_train_Std,y_train, cv=4, scoring="accuracy")
np.mean(Accuracies)
Out[36]:
In [37]:
rnd.feature_importances_
Out[37]:
In [38]:
font = {'size' : 9}
plt.rc('font', **font)
fig, ax1 = plt.subplots(figsize=(8, 4), dpi= 120, facecolor='w', edgecolor='k')
score=list((rnd.feature_importances_*100))
sort_low_high=np.sort(score, axis=0)
sort_high_low=sort_low_high[::-1]
clmns=list(X_train.columns)
sort_colms=[]
for i in range(len(sort_high_low)):
ind=score.index(sort_high_low[i])
sort_colms.append(clmns[ind])
index = np.arange(len(sort_high_low))
ax1.bar(index, sort_high_low, align='center',width=0.6, alpha=1, ecolor='black',edgecolor ='k', capsize=4,color='b')
#ax1.set_xlabel('Features',fontsize=12)
ax1.set_ylabel('Percentage of Importance (%)',fontsize=11)
ax1.set_xticks(np.arange(len(sort_colms)))
ax1.set_xticklabels(sort_colms, rotation=90)
ax1.xaxis.grid(color='k', linestyle='--', linewidth=1)
plt.title('Random Forest Algorithm to Rank Importance of Features',fontsize=12)
plt.show()

Boosting¶
Boosting is another ensemble learning applied to integrate some weak learners into some strong learner. Boosting methods generally work by sequentially train predictors, and for each training, it tries to improve its predecessor. The most important boosting techniques are Adaptive Boosting (AdaBoost) and Gradient Boosting.
Adaptive Boosting¶
Adaptive Boosting corrects its predictor by paying more attention to the training instances that are underfitting the predecessor. This leads to a new predictor for each run focusing on difficult instances. Adaptive Boosting requires a classifier such as SVM or Decision Trees. Then, it gives more weight to misclassified instances. This process is repeated for many times. Finally, ensemble is applied to make prediction. This usually makes the first classifier (SVM, Decision Trees...) more powerful (see Figure below).

Lets apply Adaptive Boosting for SVM. First without Adaptive Boosting:
SVM¶
In [39]:
from sklearn.svm import LinearSVC
# SVM Classifier model
np.random.seed(32)
svm = LinearSVC(C=1)
svm.fit(X_train_Std, y_train)
Accuracies=cross_val_score(svm,X_train_Std,y_train, cv=4, scoring="accuracy")
np.mean(Accuracies)
Out[39]:
Then apply Adaptive Boosting:
In [40]:
from sklearn.ensemble import AdaBoostClassifier
ada_svm = AdaBoostClassifier(svm, n_estimators=100,learning_rate=0.05,algorithm="SAMME",random_state=42)
ada_svm.fit(X_train_Std,y_train)
Accuracies=cross_val_score(ada_svm,X_train_Std,y_train, cv=4, scoring="accuracy")
np.mean(Accuracies)
Out[40]:
After applying Adaptive Boosting, the performance has not changed for SVM. But this is not the case all the time.
Decision Tree¶
Now apply for Decision Tree:
In [41]:
from sklearn.tree import DecisionTreeClassifier
np.random.seed(42)
tree = DecisionTreeClassifier(max_depth=2)
tree.fit(X_train_Std, y_train)
Accuracies=cross_val_score(tree,X_train_Std,y_train, cv=4, scoring="accuracy")
np.mean(Accuracies)
Out[41]:
In [42]:
ada_tree = AdaBoostClassifier(tree, n_estimators=100,learning_rate=0.5,
algorithm="SAMME",random_state=42)
ada_tree.fit(X_train_Std,y_train)
Accuracies=cross_val_score(ada_tree,X_train_Std,y_train, cv=4, scoring="accuracy")
np.mean(Accuracies)
Out[42]:
Wow! applying Adaptive Boosting has greatly improved the performance.
Gradient Boosting (for Regression)¶
Gradient Boosting is another popular Boosting algorithm. Similar to Adaptive Boosting, Gradient Boosting corrects its predecessor and then ensemble is applied at the end. The only difference is Gradient Boosting fits new predictor to the residual errors from the previous predictor (Adaptive Boosting tweaks the instance weights at every iteration).
Let’s apply Gradient Boosting for a simple regression example using Decision Trees as the base predictors. Gradient Boosting works great with regression tasks.
First generate a synthetic data and a Decision Tree is trained based on the synthetic training data:
Gradient Boosting with Decision Tree¶
In [15]:
# Quadratic training set + noise
np.random.seed(52)
n = 100
X = np.random.rand(n, 1)
y = 10-(X-0.5) **2
y = y + np.random.randn(n, 1) / 15
In [16]:
from sklearn.tree import DecisionTreeRegressor
np.random.seed(42)
tree_1 = DecisionTreeRegressor(max_depth=3,min_samples_split=20)
tree_1.fit(X, y)
Out[16]:
Now residual errors between true values and the first predictor is calculated. Then, a second DecisionTreeRegressor is trained:
In [17]:
Error_1=[y[i]-tree_1.predict(X[i].reshape(-1,1)) for i in range(len(X))]
tree_2 = DecisionTreeRegressor(max_depth=3,min_samples_split=20)
tree_2.fit(X, Error_1)
Out[17]:
Again a third regressor is trained on the residual errors made by the second predictor:
In [18]:
Error_2=[Error_1[i]-tree_2.predict(X[i].reshape(-1,1)) for i in range(len(X))]
tree_3 = DecisionTreeRegressor(max_depth=3,min_samples_split=20)
tree_3.fit(X, Error_2)
Out[18]:
Then again a forth regressor on the residual errors made by the third predictor is trained:
In [19]:
Error_3=[Error_2[i]-tree_3.predict(X[i].reshape(-1,1)) for i in range(len(X))]
tree_4 = DecisionTreeRegressor(max_depth=3,min_samples_split=20)
tree_4.fit(X, Error_3)
Out[19]:
This process can be repeated for many iteration.
Now we have an ensemble containing four trees. It can make predictions on a new instance simply by adding up the predictions of all the trees. The following code predicts 5 instances of the training set.
In [20]:
X_new=X[:5]
y_pred = sum(tree.predict(X_new) for tree in (tree_1, tree_2, tree_3, tree_4))
y_pred
Out[20]:
In [21]:
from sklearn.tree import DecisionTreeRegressor
import numpy as np
import matplotlib
import pylab as plt
font = {'size' : 10}
matplotlib.rc('font', **font)
fig,ax = plt.subplots(figsize=(12, 12), dpi= 90, facecolor='w', edgecolor='k')
fig.subplots_adjust(hspace = 0.35, wspace=0.2)
ax1=plt.subplot(3,2,1)
x1 = np.linspace(0, 1, 500).reshape(-1, 1)
y_pred = tree_1.predict(x1)
plt.xlabel("$X$",)
plt.ylabel("$y$", rotation=0)
plt.plot(X, y, "ro",markersize=6,label='Training Data')
plt.plot(x1, y_pred, "b-", linewidth=3, label='Fitted Model')
plt.title("Step 1: Train a Decision Tree Regressor", fontsize=14)
plt.legend(loc=2, fontsize=11)
ax2=plt.subplot(3,2,2)
x1 = np.linspace(0, 1, 500).reshape(-1, 1)
y_pred = tree_2.predict(x1)
plt.xlabel("$X$")
plt.ylabel("$y$", rotation=0)
plt.plot(X, Error_1, "go",markersize=6,label='Residual')
plt.plot(x1, y_pred, "m-", linewidth=3, label='Fitted Model')
plt.legend(loc=2, fontsize=11)
plt.title("Step 2: Residual and Tree Predictions 1", fontsize=14)
ax3=plt.subplot(3,2,3)
y_pred = sum(tree.predict(x1) for tree in (tree_1, tree_2))
plt.xlabel("$X$")
plt.ylabel("$y$", rotation=0)
plt.plot(X, y, "ro",markersize=6,label='Training Data')
plt.plot(x1, y_pred, "b-", linewidth=3, label='Fitted Model')
plt.legend(loc=2, fontsize=11)
plt.title("Ensemble Prediction 1", fontsize=14)
ax4=plt.subplot(3,2,4)
y_pred = tree_3.predict(x1)
plt.xlabel("$X$")
plt.ylabel("$y$", rotation=0)
plt.plot(X, Error_2, "go",markersize=6,label='Residual')
plt.plot(x1, y_pred, "m-", linewidth=3, label='Fitted Model')
plt.legend(loc=2, fontsize=11)
plt.title("Step 3: Residual and Tree Predictions 2", fontsize=14)
ax5=plt.subplot(3,2,5)
y_pred = sum(tree.predict(x1) for tree in (tree_1, tree_2, tree_3))
plt.xlabel("$X$")
plt.ylabel("$y$", rotation=0)
plt.plot(X, y, "ro",markersize=6,label='Training Data')
plt.plot(x1, y_pred, "b-", linewidth=3, label='Fitted Model')
plt.legend(loc=2, fontsize=11)
plt.title("Ensemble Prediction 2", fontsize=14)
ax4=plt.subplot(3,2,6)
y_pred = tree_4.predict(x1)
plt.xlabel("$X$")
plt.ylabel("$y$", rotation=0)
plt.plot(X, Error_3, "go",markersize=6,label='Residual')
plt.plot(x1, y_pred, "m-", linewidth=3, label='Fitted Model')
plt.legend(loc=2, fontsize=11)
plt.title("Step 4: Residual and Tree Predictions 3", fontsize=14)
plt.show()

If this process is repeated many times it may leads to overfitting. All this process can be automatically applied by Scikit-Learn’s XGBoost. You should first install it by typing pip install xgboost in Anaconda Prompt and press enter.
In [22]:
import xgboost
xgb_reg = xgboost.XGBRegressor()
xgb_reg.fit(X, y)
Out[22]:
In [23]:
font = {'size' : 10}
matplotlib.rc('font', **font)
fig,ax = plt.subplots(figsize=(12, 12), dpi= 90, facecolor='w', edgecolor='k')
fig.subplots_adjust(hspace = 0.35, wspace=0.2)
ax1=plt.subplot(3,2,1)
x1 = np.linspace(0, 1, 500).reshape(-1, 1)
y_pred = xgb_reg.predict(x1)
plt.xlabel("$X$",)
plt.ylabel("$y$", rotation=0)
plt.plot(X, y, "ro",markersize=6,label='Training Data')
plt.plot(x1, y_pred, "b-", linewidth=2, label='Fitted Model')
plt.title("Apply xgboost without early \n stopping (sever overfitting)", fontsize=14)
plt.legend(loc=2, fontsize=11)
plt.show()

xgboost has early stopping (early_stopping_rounds) to avoid overfitting. As we discussed before, early stopping needs validation set. So the training set can be divided into smaller training set and validation set:
In [24]:
# Cocatenate X and y
Xy=np.concatenate((X,y),axis=1)
In [25]:
from sklearn.model_selection import train_test_split
# Split the training set to 15% varidation set and smaller traning set
Smaller_X, Validation = train_test_split(Xy, test_size=0.15, random_state=40)
In [26]:
import warnings
warnings.filterwarnings('ignore')
xgb_reg.fit(Smaller_X[:,0].reshape(-1,1), Smaller_X[:,1].reshape(-1,1),
eval_set=[(Validation[:,0].reshape(-1,1),
Validation[:,1].reshape(-1,1))], early_stopping_rounds=2)
Out[26]:
In [27]:
font = {'size' : 10}
matplotlib.rc('font', **font)
fig,ax = plt.subplots(figsize=(12, 12), dpi= 90, facecolor='w', edgecolor='k')
fig.subplots_adjust(hspace = 0.35, wspace=0.2)
ax1=plt.subplot(3,2,1)
x1 = np.linspace(0, 1, 500).reshape(-1, 1)
y_pred = xgb_reg.predict(x1)
plt.xlabel("$X$",)
plt.ylabel("$y$", rotation=0)
plt.plot(X, y, "ro",markersize=6,label='Training Data')
plt.plot(x1, y_pred, "b-", linewidth=2, label='Fitted Model')
plt.title("Apply xgboost with early \n stopping (not overfitting)", fontsize=14)
plt.legend(loc=2, fontsize=11)
plt.show()

Random Forest for Regression¶
Random Forest can also be applied for regression task as we saw in Lecture 4. Lets apply Random Forest for the synthetic data.
In [28]:
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_predict
forest_reg = RandomForestRegressor()
forest_reg.fit(X, y)
y_pred = cross_val_predict(forest_reg, X, y, cv=4)
In [29]:
font = {'size' : 10}
matplotlib.rc('font', **font)
fig,ax = plt.subplots(figsize=(12, 12), dpi= 90, facecolor='w', edgecolor='k')
fig.subplots_adjust(hspace = 0.35, wspace=0.2)
ax1=plt.subplot(3,2,1)
x1 = np.linspace(0, 1, 500).reshape(-1, 1)
y_pred = forest_reg.predict(x1)
plt.xlabel("$X$",)
plt.ylabel("$y$", rotation=0)
plt.plot(X, y, "ro",markersize=6,label='Training Data')
plt.plot(x1, y_pred, "b-", linewidth=2, label='Fitted Model')
plt.title("Apply Random Forest Regression ", fontsize=14)
plt.legend(loc=2, fontsize=11)
plt.show()

Stacking¶
Ensemble Learning also very useful to apply near the end of project when a few good and promising predictors are built to integrate them into an even stronger predictor. We saw that soft and hard voting can be simply applied to aggregate predictors to reach a strong learner. Hard voting aggregates the predictions of each classifier and predict the class that gets the most votes. Soft voting works by averaging the probability of each class and predict a class with the highest probability. Soft voting often achieves higher performance than Hard voting due to giving more weight to highly confident votes. Instead of using simple functions to aggregate the predictions of all predictors, staking approach trains a model such as Random Forest to perform this aggregation. The final predictor takes these predictions as inputs and makes the final prediction. Staking may lead to even better prediction than the best individual if predictors are independent from each other (Géron 2019). Figure below shows an schematic illustration of staking approach.
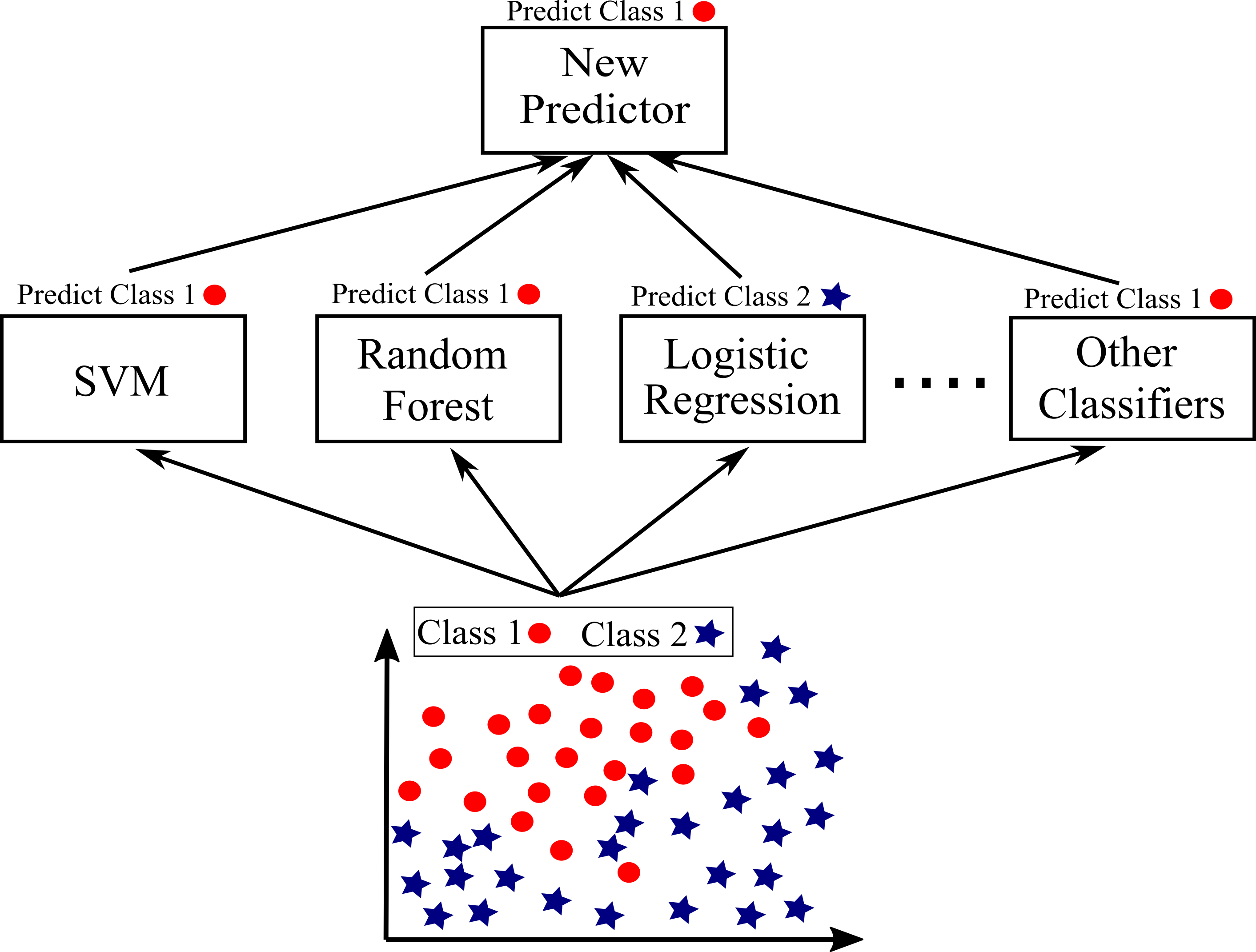
Lets apply stacking approach for Logistic Regression, Random Forest, Stochastic Gradient Descent and SVM. But first, look at performance of each predictor hard and soft voting on the test set.
In [30]:
from sklearn.linear_model import SGDClassifier
from sklearn.dummy import DummyClassifier
log = LogisticRegression(random_state=10)
rnd = RandomForestClassifier(random_state=10)
svm = SVC(C=10,random_state=10)
sgd = SGDClassifier(random_state=10)
dmy = DummyClassifier(random_state=42)
clf=['Dummy Classifier','Logistic Regression ', 'Random Forest ', 'SVM','SGD ', 'Hard Voting ', 'Soft Voting ']
i=0
pre_acc=[]
for clfier in (dmy,log, rnd, svm, sgd, hard_voting, soft_voting):
clfier.fit(X_train_Std, y_train)
y_pred = clfier.predict(X_test_Std)
acc=accuracy_score(y_test, y_pred)
pre_acc.append(acc)
print(clf[i], acc)
i+=1
Soft voting gives the highest accuracy. Now, we apply stacking to see if you can get higher accuracy.
In [31]:
estimators=[log,rnd,svm,sgd]
x_Predictions = np.zeros((len(X_train_Std), len(estimators)), dtype=np.float32)
# Apply estimators on Validation data set
for index, estimator in enumerate(estimators):
estimator.fit(X_train_Std, y_train)
y_pred = cross_val_predict(estimator, X_train_Std, y_train, cv=4)
x_Predictions[:, index] = np.ravel(y_pred)
# Train a new Random Forest for prediction
New_rnd = RandomForestClassifier()
New_rnd.fit(x_Predictions, y_train)
# Predict result by stacking on test set
x_test_predictions = np.zeros((len(X_test_Std), len(estimators)), dtype=np.float32)
for index, estimator in enumerate(estimators):
x_test_predictions[:, index] = np.ravel(estimator.predict(X_test_Std))
y_pred = New_rnd.predict(x_test_predictions)
acc=accuracy_score(y_test, y_pred)
pre_acc.append(acc)
clf=clf+['stacking']
print('Stacking ', acc)
Recap Plots¶
In [32]:
import matplotlib.patheffects as pe
font = {'size' :13}
matplotlib.rc('font', **font)
fig, ax1 = plt.subplots(figsize=(13, 5), dpi= 120, facecolor='w', edgecolor='k')
plt.plot(clf,pre_acc,'bs-',linewidth=1,path_effects=[pe.Stroke(linewidth=3, foreground='k'), pe.Normal()],
markersize=12,label='Accuracy',markeredgecolor='k')
ax1.bar(clf,pre_acc,lw =2, align='center',width=0.5, alpha=1, ecolor='black', edgecolor='k',capsize=1,color='b')
plt.ylim((0.2, 0.98))
ax1.set_xticklabels(clf, rotation=25)
ax1.xaxis.grid(color='k', linestyle='--', linewidth=0.8)
ax1.yaxis.grid(color='k', linestyle='--', linewidth=0.8)
plt.ylabel('Accuracy ',fontsize='17')
plt.title('Accuracy for Test set for 7 Classifier',fontsize='18')
plt.show()
