Summary
Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. Text Similarity is one of the essential techniques of NLP which is being used to find the closeness between two chunks of text by surface or meaning. Computers require data to be converted into a numeric format to perform any machine learning task. On the surface is only word level similarity (lexical), these two phrases appear very similar as 3 of the 4 unique words are an exact overlap. This approach does not take into account the actual meaning behind words or the entire phrase in context. So, semantic similarity can be considered to focus on phrase/paragraph levels (or lexical chain level) where a piece of text is broken into a relevant group of related words prior to computing similarity. This notebook first presents an introduction to data processing for NLP and then text similarity for both surface and meaning level are applied. The approaches are Jaccard similarity, Cosine similarity, Inverse Document Frequency, Glove pre-trained method and Word Mover Distance.
Python functions and data files to run this notebook are in my Github page.
#nltk.download()
import pandas as pd
pd.set_option('display.max_columns', None)
import numpy as np
import xlrd
from math import log
import scipy
import re
import nltk
import warnings
warnings.filterwarnings('ignore')
from IPython.display import HTML
from functions import* # import require functions to run this notebook
Tokenization¶
The first step of NLP is to separate a corpus into documents and a document into words. This process is called tokenization because the resulting tokens contain words and punctuations. Although the process sounds trivial, there are many non-trivial language-specific issues. Think about the different uses of periods, commas, and quotes. The Natural Language Toolkit (nltk) Python package provides implementations and pre-trained transformers for many NLP algorithms, as well as for word tokenization.
document="Almost before we knew it, we had left the ground. The unknown holds its grounds."
#Tokenization
from nltk.tokenize import word_tokenize
tokens = word_tokenize(document)
tokens
Other nltk tokenizers are as below:
sent_tokenize¶
It tokenizes a document into sentences:
from nltk.tokenize import sent_tokenize
sent_tokenize(document)
regexp_tokenize¶
It tokenizes a string or document based on a regular expression pattern:
from nltk.tokenize import regexp_tokenize
s = "Good muffins cost $3.88\nin New York. Please buy me\ntwo of them.\n\nThanks."
regexp_tokenize(s, pattern='\w+|\$[\d\.]+|\S+')
TweetTokenizer¶
Usually used for tweet tokenization, which allows to separate hashtags, mentions and lots of exclamation points:
from nltk.tokenize import TweetTokenizer
tt = TweetTokenizer()
tweet = "This is a cooool #dummysmiley: :-) :-P <3 and some arrows < > -> <-- @remy: This is waaaaayyyy too much for you!!!!!!"
print(tt.tokenize(tweet))
Bag of Words (BoW)¶
BoW only counts the words in document after tokenization. The more frequent a word is, the more importance it could have in a text. Based on the number of words used in a text, significant words can be defined:
from collections import Counter
words="Almost before we knew it, we had left the ground. The unknown holds its grounds."
tokens=word_tokenize(words)
Counter(tokens)
As you can see, data processing should be applied before using BOW
Stop words¶
In the preceding code, word.islanum() function is used to extract only alphanumeric tokens and make them all lowercase. The preceding list of words already looks much better than the initial naive model. However, it still contains a lot of unnecessary words, such as the, we, had, and so on, which don't convey any information.
In order to filter out the noise for a specific language, it makes sense to remove these words that appear often in texts and don't have any semantic meaning. The so-called stop words are usually removed using a pre-trained look-up dictionary. This can be done by pre-trained nltk library in Python.
# Remove punctuation
words = [word.lower() for word in tokens if word.isalnum()]
words
#Stop words
from nltk.corpus import stopwords
nltk.download('stopwords')
stopword_set = set(stopwords.words('english'))
words = [word for word in words if word not in stopword_set]
words
Stemming¶
Removing the affixes of words to obtain the stem of a word is also called stemming. Stemming refers to a rule-based (heuristic) approach to transform each occurrence of a word into its word stem. Here is a simple example of some expected transformations: cars -> car
############## Stemming ##############
from nltk.stem import PorterStemmer
def stem(words):
stemmer = PorterStemmer()
return [stemmer.stem(word) for word in words]
words = stem(words)
words
Lemmatization¶
When looking at the stemming examples, limitations of the approach is obvious. For example, irregular verb conjugations—such as "are", "am", or "is" that should all consider as "be"? This is lemmatization which tries to solve using a pre-trained set of vocabulary and conversion rules, called lemmas. The lemmas are stored in a look-up dictionary and look similar to the following transformations:
are -> be
is -> be
taught -> teach
better -> good
There is one very important point to make when speaking about lemmatization. Each lemma needs to be applied to the correct word type for nouns, verbs, adjectives, and so on. The reason for this is that a word can be either a noun or a verb in the past tense. Left could be an adjective or the past tense of leave. So, we also need to extract the word type from the word in a sentence. The process is called Point of Speech (POS) tagging.
Luckily, the nltk library has us covered once again. To estimate the correct POS tag, we also need to provide the punctuation:
#tokens_pos = categorize(tokens)
#words_pos = [pos for w, pos in zip(tokens, tokens_pos) if is_no_punctuation(w) and is_no_stopword(w)]
#print('Word categories:', words_pos)
############## Lemmatization ##############
from nltk.corpus import wordnet
from nltk.stem import WordNetLemmatizer
nltk.download('wordnet')
lemmatizer = WordNetLemmatizer()
def categorize(words):
tags = nltk.pos_tag(words)
return [tag for word, tag in tags]
def lemmatize(words, tags):
lemmatizer = WordNetLemmatizer()
tag_dict = {"J": wordnet.ADJ, "N": wordnet.NOUN, "V": wordnet.VERB, "R": wordnet.ADV}
pos = [tag_dict.get(t[0].upper(), wordnet.NOUN) for t in tags]
return [lemmatizer.lemmatize(w, pos=p) for w, p in zip(words, pos)]
words_pos = categorize(words)
words = set(lemmatize(words, words_pos))
words
words_pos
More accurate BOW is:
Counter(words)
Spell checking¶
See these pages stackoverflow1, stackoverflow2
It is required to load to copy these 125k words, sorted by frequency into a text file, name the file words-by-frequency.txt.
A cost dictionary is built using Zipf's law: it states that given a large sample of words used, the frequency of any word is inversely proportional to its rank in the frequency table. In fact, the word with rank $n$ in the list of words has probability roughly:
$\large probability=\frac{1}{n\times log (N)}$
where $N$ is the number of words in the dictionary. Instead of directly using the probability we use a cost defined as the logarithm of the inverse of the probability as $-log(probability)$ to avoid overflows. It leads to equation below:
$\large probability=log((n)\times log(N)) $
import re
# assuming Zipf's law (https://en.wikipedia.org/wiki/Zipf%27s_law)
# cost = -math.log(probability).
with open("./data/words-by-frequency.txt") as f:
words = [line.strip() for line in f.readlines()]
wordcost = dict((k, log((i+1)*log(len(words)))) for i,k in enumerate(words))
# Maximum length for words
maxword = max(len(x) for x in words)
document="""This is a tepid docu-drama that covers no new ground,
reworks all the cliches and is sloppy with facts. For example, Munich is a very flat city.
So why is it hilly in the movie? For example, the end of the Great War in 1918 was
not a surrender but an armistice. Yet it is annoufnced as a surrender. For example,
European news vendors did not (and do not) shout headlines as they hawk their papers.
Yet this sctrictly American custom is employed in the film. For example, the Nazis did not
adopt the German eagle until after they had taken power but there it is on the lectern as
Hitler delivers one of his stem winders. Indeed, most of this disappointing production consists
of little more than Hitlerian oratory. The movie also perpetuates the mycth that the beer hall
putsch was hatched at the Munich Hoffbrauhaus. It was not. Robert Carlyle does a fine portrayal
of his subject. But his supporting cast is adequate at best and very often not even that. These
comments are based on the first episode only. One only can hope the second will be better but don't bet on it."""
result_df=spell_check(document,maxword=maxword,wordcost=wordcost)
result_df
Jaccard Similarity¶
Jaccard similarity or intersection over union is defined as size of intersection divided by size of union of two sets. Let’s take example of two sentences:
document1='AI is our friend and it has been friendly'
document2='AI and humans have always been friendly'
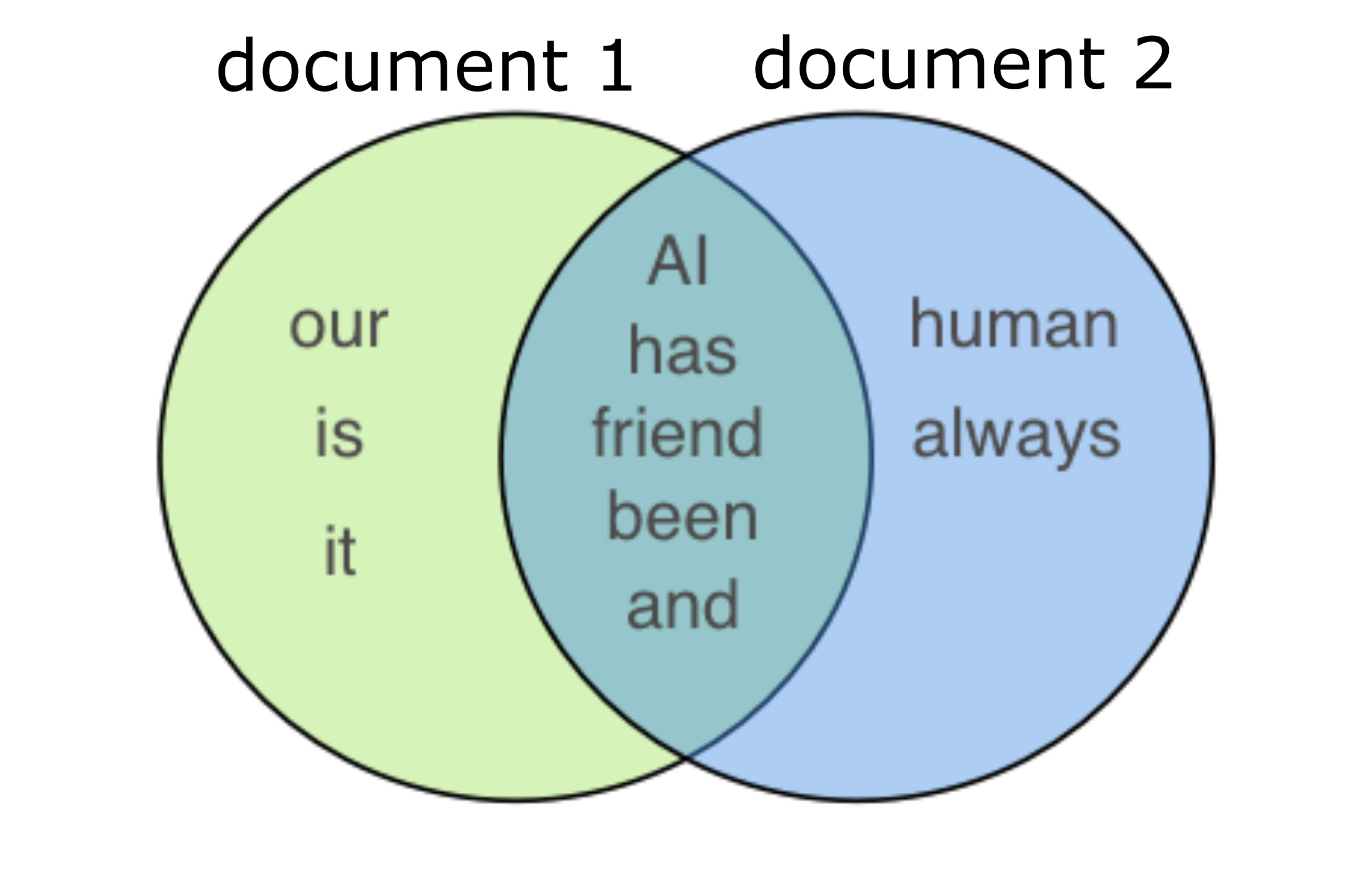
Jaccard_Similarity(document1,document2,stopwords=False)
For the above two sentences, the Jaccard similarity is 5/(3+5+2) = 0.5 (stop words are not removed) which is size of intersection of the set divided by total size of set.
The issue with Jaccard similarity is it not able to capture semantic similarity nor lexical semantic sentences. It only relies on number of common words.
CountVectorizer Method + Cosine Similarity¶
import pylab as plt
import math
def dotproduct(v1, v2):
return sum((a*b) for a, b in zip(v1, v2))
def length(v):
return math.sqrt(dotproduct(v, v))
def angle(v1, v2):
return math.degrees(math.acos(dotproduct(v1, v2) / (length(v1) * length(v2))))
- CountVectorizer is a great tool provided by the scikit-learn library in Python. It is used to transform a given text into a vector on the basis of the frequency (count) of each word that occurs in the entire text. This is helpful when we have multiple such texts, and we wish to convert each word in each text into vectors (for using in further text analysis).
- Cosine similarity calculates similarity by measuring the cosine of angle between two vectors. It is a judgment of orientation and not magnitude: two vectors with the same orientation have a cosine similarity of 1, two vectors oriented at 90° relative to each other have a similarity of 0, independent of their magnitude. If the angle is bigger than 90°, the similarity will be negative.
- The cosine similarity is advantageous because even if the two similar documents are far apart by the Euclidean (yoo·kli·dee·uhn) distance (due to the size of the document), chances are they may still be oriented closer together. The smaller the angle, higher the cosine similarity.
$\large Similarity= cos(\theta)=\frac{\textbf{A}.\textbf{B}}{\left| \left| \textbf{A}\right| \right|\, \left| \left| \textbf{B} \right| \right|}=\frac{\sum_{i=1}^{n} A_{i}B_{i}}{\sqrt{\sum_{i=1}^{n} A_{i}^{2}}\sqrt{\sum_{i=1}^{n} B_{i}^{2}}}$

Documents should be converted to vectors first and then cosine of angle between two documents is calculated. See example below:
document1='AI is our friend and it has been friendly'
document2='AI and humans have always been friendly'
print('document1=', document1)
print('document2=', document2)
cos,df=Cosine_Similarity(document1,document2,stopwords=True,counts=True)
They can be converted to vector based on the frequency (count) of each word (after removing stop words) as below:
df
Then, cosine similarity calculates similarity by measuring the cosine of angle between two vectors, document1 and document2:
print('Cosine Similarity=',cos)
Here is a 2D example for Cosine Similarity:
document1='friend humans'
document2='humans'
cos,df=Cosine_Similarity(document1,document2,stopwords=True,counts=True)
a=df.iloc[0].values
b=df.iloc[1].values
print('Cosine Similarity=',cos)
print('\n Vector for document1 and 2')
df
font = {'size' :9}
plt.rc('font', **font)
fig, ax1 = plt.subplots(figsize=(18, 5), dpi= 100, facecolor='w', edgecolor='k')
ax1=plt.subplot(1,3,1)
plt.annotate('',
xy=(a[0],a[1]),
xytext=(0, 0),
fontsize=20,
arrowprops=dict(facecolor='blue',width=5)
)
plt.text(a[0],a[1], 'document 1', color='blue',fontsize=15)
plt.annotate('',
xy=(b[0],b[1]),
xytext=(0,0),
fontsize=20,
arrowprops=dict(facecolor='red', width=5)
)
plt.text(b[0],b[1], 'document 2', color='red',fontsize=15)
plt.title(f'{np.round(math.cos(math.radians(angle(a,b))),2)*100}% Similarity',fontsize=18)
plt.xlabel('x',fontsize=20)
plt.ylabel('y',fontsize=20)
plt.ylim(0,1.5)
plt.xlim(0,1.5)
plt.text(0.1,1.3, f'θ={int(angle(a,b))}°, Cos(θ)={np.round(math.cos(math.radians(angle(a,b))),3)}', color='k',rotation=0,fontsize=15)
plt.show()

Word Importance by Inverse Document Frequency ( tf-idf)+ Cosine Similarity¶
- One particular downside of CountVectorizer Method is that the more often a term occurs, the higher its count (and therefore weight) will get. This is a problem since now any term that is not a stop word and appears often in the text will receive a high weight—independent of the importance of the term to a certain document.
- Instead of an absolute count of terms in a context, the count of terms in the context relative to a corpus of documents is calculated. By doing so, higher weight is given to terms that appear only in a certain context, and reduced weight to terms that appear in many different documents.
The term frequency (ft) counts all the terms in a document. The inverse document frequency (idf) is computed by dividing the total number of documents (N) by the counts of a term in all documents (fd). The idf term is usually log-transformed as the total count of a term across all documents can get quite large.
Term frequency-inverse document frequency weight is calculated by:
$\large \omega_{i,j}=tf_{i,j}.log(\frac{N}{df_{i}})$
$\omega_{i,j}$ → weight of term $i$ in document $j$
$tf_{i,j}$ → term frequency (number of occurrences) of term $i$ in document $j$
$N$ → number of documents in the corpus
$df_{i}$ → number of documents containing term $i$
For example, if number of documents in corpus is 30 and number of documents containing the "library" are 20, and frequency of "library" in the document is 8, then TF-idf wight for "library" is:
$\Large 8\times log(\frac{30}{20})=3.24$
See this page for more information.
document1='AI is our friend and it has been friendly'
document2='AI and humans have always been friendly'
print('document1=', document1)
print('document2=', document2)
print('\n')
cos,df=Cosine_Similarity_tf_idf(document1,document2,stopwords=True,counts=True, tf_idf=True)
print('Cosine Similarity (tf_idf)=',cos)
print('\n Vector for document1 and 2')
df
Glove Pre-trained Method + Cosine Similarity¶
- Previous technique cannot achieve similarity between two documents in term of meaning (semantic). For example, the meaning of two sentences below are very close to each other but there is no words in common so cosine (tf_idf) gives zero similarity:
document1='President greets the press in Chicago'
document2='Biden speaks to media in Illinois'
print('document1=', document1)
print('document2=', document2)
cos,df=Cosine_Similarity_tf_idf(document1,document2,stopwords=True,counts=True, tf_idf=True)
print('Cosine Similarity (tf_idf)=',cos)
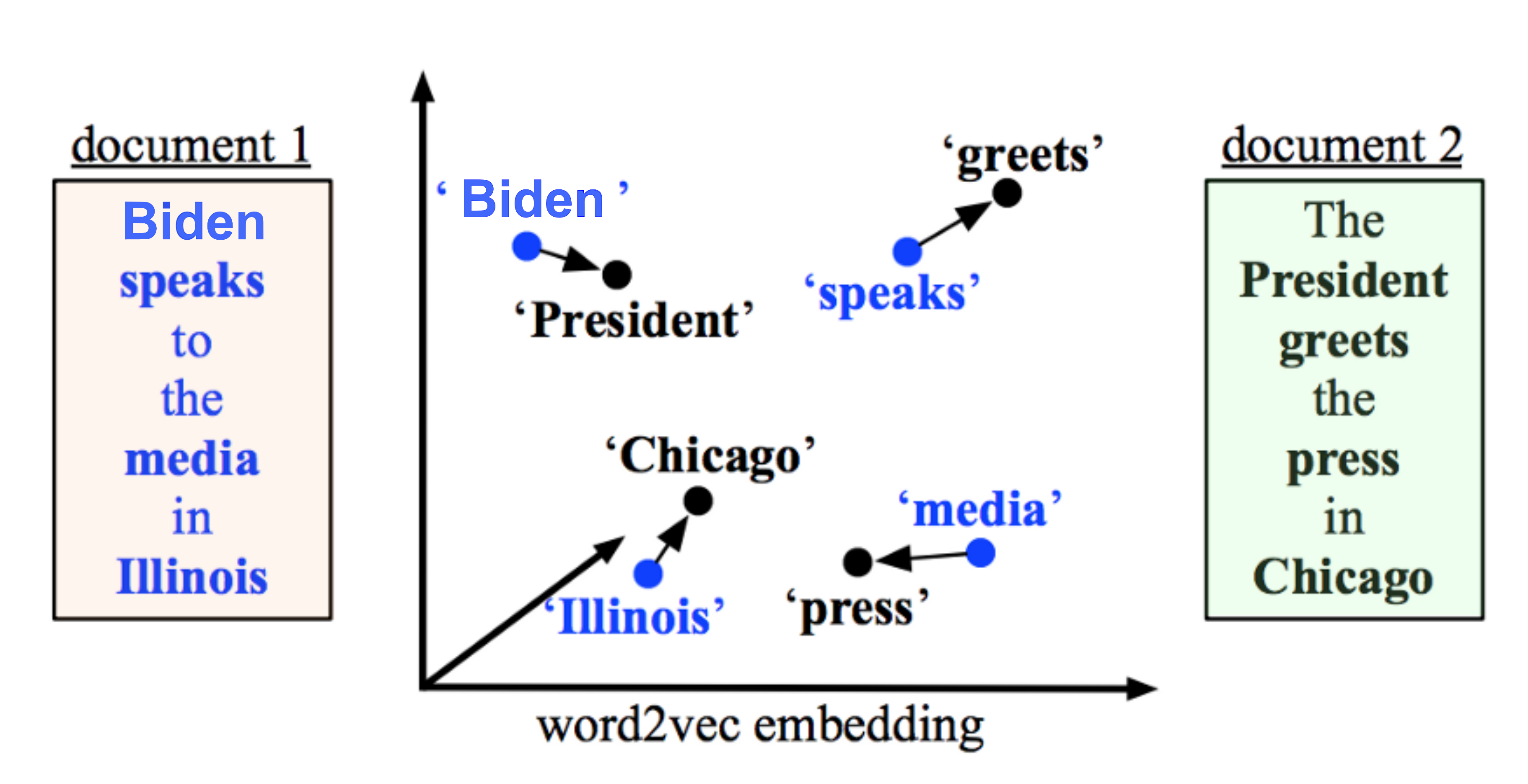
Pre-trained models can be used to measure how frequently words co-occur with one another in a large corpus by calculating word vectors. A word vector is an attempt to mathematically represent the meaning of a word. In essence, a computer goes through some text (ideally a lot of text) and calculates how often words show up next to each other. These frequencies are represented with numbers.
For example in Figure below, king - queen is equal man - women, Germany to Berlin as China to Beijing. Deep learning algorithms are used to create word vectors and has been able to achieve this meaning based on how much those words are used through the text

Image retrieved from https://developers.google.com/machine-learning/crash-course/embeddings/translating-to-a-lower-dimensional-space
The GloVe model is trained on the non-zero entries of a global word-word co-occurrence matrix. It is a high speed word embedding technique which is trained on word-word co-occurrence probabilities and have the potential for achieve some form of meaning which can be encoded as vector differences.
The pre-trained GloVe model can be downloaded from https://nlp.stanford.edu/projects/glove/ as text file.
Each line of the text file contains a word, followed by N numbers. The N numbers describe the vector of the word’s position. N may vary depending on which vectors you downloaded, for this notebook N is 50 (glove.6B.50d).
Here is example line from the text file:
| Word | vector 1 | vector 2 | ... | vector 50 |
|---|---|---|---|---|
| will | 0.81544 | 0.30171 | ... | 0.5472 |
| business | 0.0236 | 0.133 | ... | 0.0231 |
| osipov | -0.83172 | 0.51419 | ... | 0.35741 |
| burgo | 0.23552 | -0.1543 | ... | 0.33062 |
| . | . | . | ... | . |
| . | . | . | ... | . |
# Load Glove Model
gloveFile = "data\\glove.6B.50d.txt"
def loadGloveModel(gloveFile):
print ("Loading Glove Model")
with open(gloveFile, encoding="utf8" ) as f:
content = f.readlines()
model = {}
for line in content:
splitLine = line.split()
word = splitLine[0]
embedding = np.array([float(val) for val in splitLine[1:]])
model[word] = embedding
print ("Done.",len(model)," words loaded!")
return model
model_Glove = loadGloveModel(gloveFile)
document1='Biden speaks to the media in Illinois'
document2='The president greets the press in Chicago'
After tokenization and data processing, the mean of all dimensions for the words of each document is calculated and then cosine similarity is computed for the the calculated means.
See below how to calculate mean of vectors for the words in document 1
# Calculate the mean of the words for document1
words_doc1=['biden', 'speaks', 'media', 'illinois']
vector1=np.mean([model_Glove[word] for word in words_doc1],axis=0)
vector1
# Calculate the mean of the words for document2
words_doc2=['president', 'greets', 'press', 'chicago']
vector2=np.mean([model_Glove[word] for word in words_doc2],axis=0)
vector2
Here is cosine similarity between two vectors:
cosine = 1-scipy.spatial.distance.cosine(vector1, vector2)
cosine
Function Glove_Cosine_Embedding automatically do all these steps as below:
cosine_all,df=Glove_Cosine_Embedding(document1,document2,model_Glove,Lemmatization=False,stopwords=True)
print (cosine_all)
Here are cosine similarity between individual words of documents. As expected, 'media' and 'press' has the highest similarity, followed by 'illinois' and 'chicago'.
for iwords in words_doc1:
for jwords in words_doc2:
cosine_=1-scipy.spatial.distance.cosine(model_Glove[iwords], model_Glove[jwords])
print (f"""Cosine similarity between word vectors of '{iwords}' and '{jwords}' is {cosine_}""")
font = {'size' : 10}
plt.rc('font', **font)
fig, ax=plt.subplots(figsize=(7, 4), dpi= 110, facecolor='w', edgecolor='k')
matrix_occure_prob(df,title='Matrix for Cosine Similarity for \n Words of two Documents',axt=ax,pad=15,
lable1='document 2 ',vmin=0,vmax=0.7,cbar_per=False,lable2='document 1',
num_ind=True,txtfont=12,xline=False)

Word Mover’s Distance¶
- Word Mover’s Distance (WMD) is based on recent results in word embeddings that learn semantically meaningful representations for words from local co-occurrences in sentences. WMD leverages the results of advanced embedding techniques like word2vec and Glove.
- Word Mover’s Distance (WMD) enables us to assess the “distance” between two documents in a meaningful way even when they have no words in common. It has been shown to outperform many of the state-of-the-art methods.
The distance between two text documents A and B is calculated by the minimum cumulative distance that words from the text document A needs to travel to match exactly the point cloud of text document B. Watch this video on YouTube that shows how to calculate the minimum cumulative distance.
- gensim Python library is excellent to implement word movers distance techniques on word embeddings.
The WMD distance has several intriguing properties:
- It is hyper-parameter free and straight-forward to understand and use;
- It is highly interpretable as the distance between two documents can be broken down and explained as the sparse distances between few individual words
- It naturally incorporates the knowledge encoded in the word2vec / Glove space and leads to high retrieval accuracy.
First GoogleNews-vectors-negative300.bin.gz should be downloaded from here (warning: 1.5 GB). It can be loaded by gensim model as below:
from time import time
start = time()
import os
from gensim import models
model_WMD = models.KeyedVectors.load_word2vec_format('./data/GoogleNews-vectors-negative300.bin.gz', binary=True)
print('Cell took %.2f seconds to run.' % (time() - start))
document1='President greets the press in Chicago'
document2='Biden speaks to media in Illinois'
There are three steps below to measure WMD distance:
- Step 1
# CountVectorizer to get unique words
vect = CountVectorizer(stop_words="english").fit([document1, document2])
print("Unique words are: ", ", ".join(vect.get_feature_names()))
- Step 2
# Calculate distance between words from WMD
list_=vect.get_feature_names()
D_=np.zeros((len(list_),len(list_)))
for ii in range(len(list_)):
for jj in range(len(list_)):
D_[ii,jj]=model_WMD.wmdistance([list_[ii]],[list_[jj]])
- Step 3
Finally, we need to apply Earth Mover’s Distance which is a measure of the distance between two probability distributions over a region D. Informally, if the distributions are interpreted as two different ways of piling up a certain amount of earth (dirt) over the region D, the EMD is the minimum cost of turning one pile into the other; where the cost is assumed to be the amount of dirt moved times the distance by which it is moved. See a simple example below:
from pyemd import emd
first_histogram = np.array([0.0, 1.0])
second_histogram = np.array([5.0, 3.0])
distance_matrix = np.array([[0.0, 0.5],
[0.5, 0.0]])
emd(first_histogram, second_histogram, distance_matrix)
Now we can apply EMD to calculate the distance between two distributions:
v_1, v_2 = vect.transform([document1, document2])
v_1 = v_1.toarray().ravel()
v_2 = v_2.toarray().ravel()
# pyemd needs double precision input
v_1 = v_1.astype(np.double)
v_2 = v_2.astype(np.double)
v_1 /= v_1.sum()
v_2 /= v_2.sum()
D_ = D_.astype(np.double)
#D_ /= np.max(D_) # just for comparison purposes
print("d(doc_1, doc_2) = {:.2f}".format(emd(v_1, v_2, D_)))
All the steps above can be automatically applied by Word_Mover_Distance function:
document1='Biden speaks to the media in Illinois'
document2='The president greets the press in Chicago'
WMD_all,df_WMD=Word_Mover_Distance(document1,document2,model_WMD,Lemmatization=False, stopwords=True)
print ('Distance between two documents is:', np.round(WMD_all,2))
Figure below shows Word Mover Distance between the words of document 1 and document 2
font = {'size' : 10}
plt.rc('font', **font)
fig, ax=plt.subplots(figsize=(7, 4), dpi= 110, facecolor='w', edgecolor='k')
matrix_occure_prob(df_WMD,vmin=0.4,vmax=1.2,title='Two Sentence_Word Mover Distance',num_ind=True,axt=ax,pad=15,
txtfont=12,lable1='document 2 ',lable2='document 1',label='Word Mover Distance',xline=False)

Here are Word Mover Distance between individual words of documents. 'speaks' and 'press' has the lowest distance, followed by 'biden' and 'president'. Word Mover Distance cannot detect low distance between 'illinois' and 'chicago'
Example¶
Here is a corpus of 10 documents. We want to calculate lexical (Jaccard and tf-idf) and semantical similarity (Glove and Word Mover's Distance):
corpus = ["Global warming is happening",
"The weather is not good to play golf today",
"Never compare an apple to an orange",
"Apple and orange are completely different from each other",
"Ocean temperature is rising rapidly",
"AI has taken the world by storm",
"It is rainy today so we should postpone our golf game",
"I love reading books than watching TV",
"People say I am a bookworm, in fact, I do not want to waste my time on TV",
"AI has transformed the way the world works"]
Lexical Similarity¶
Jaccard Similarity¶
df=pd.DataFrame()
for doc1 in corpus:
sim_all=[]
for doc2 in corpus:
tmp=Jaccard_Similarity(doc1,doc2,stopwords=True)
sim_all.append(tmp)
df[doc1]=sim_all
df.index=corpus
font = {'size' : 16}
plt.rc('font', **font)
fig, ax=plt.subplots(figsize=(15, 10), dpi= 110, facecolor='w', edgecolor='k')
matrix_occure_prob(df,title='Jaccard Similarity Matrix',lable1='',vmin=0, pad=10,axt=ax,
vmax=0.8,cbar_per=False,lable2='',num_ind=True,txtfont=15,xline=False,fontsize=22,
lbl_font=14,label='Jaccard Similarity',rotation_x=30)

tf-idf+ Cosine Similarity¶
df=pd.DataFrame()
for doc1 in corpus:
sim_all=[]
for doc2 in corpus:
tmp=Cosine_Similarity_tf_idf(doc1,doc2,stopwords=True, tf_idf=True)
sim_all.append(tmp)
df[doc1]=sim_all
df.index=corpus
font = {'size' : 16}
plt.rc('font', **font)
fig, ax=plt.subplots(figsize=(15, 10), dpi= 110, facecolor='w', edgecolor='k')
matrix_occure_prob(df,title='tf-idf Similarity Matrix',lable1='',vmin=0, pad=10,axt=ax,
vmax=0.8,cbar_per=False,lable2='',num_ind=True,txtfont=15,xline=False,fontsize=22,
lbl_font=14,label='tf-idf Similarity',rotation_x=30)

Semantical Similarity¶
Glove Model + Cosine Similarity¶
df=pd.DataFrame()
for doc1 in corpus:
sim_all=[]
for doc2 in corpus:
tmp,_=Glove_Cosine_Embedding(doc1,doc2,model_Glove,stopwords=True)
sim_all.append(tmp)
df[doc1]=sim_all
df.index=corpus
font = {'size' : 16}
plt.rc('font', **font)
fig, ax=plt.subplots(figsize=(15, 10), dpi= 110, facecolor='w', edgecolor='k')
matrix_occure_prob(df,title='Glove Model Similarity Matrix',lable1='',vmin=0, pad=10,axt=ax,
vmax=1,cbar_per=False,lable2='',num_ind=True,txtfont=15,xline=False,fontsize=22,
lbl_font=14,label='Glove Model Similarity',rotation_x=30)

Word Mover’s Distance¶
df=pd.DataFrame()
for doc1 in corpus:
sim_all=[]
for doc2 in corpus:
tmp,_=Word_Mover_Distance(doc1,doc2,model_WMD, stopwords=True)
sim_all.append(tmp)
df[doc1]=sim_all
df.index=corpus
font = {'size' : 16}
plt.rc('font', **font)
fig, ax=plt.subplots(figsize=(15, 10), dpi= 110, facecolor='w', edgecolor='k')
matrix_occure_prob(df,title='Word Mover’s Distance Matrix',lable1='',vmin=0.8, pad=10,axt=ax,
vmax=1.5,cbar_per=False,lable2='',num_ind=True,txtfont=15,xline=False,fontsize=22,
lbl_font=14,label='Word Mover’s Distance Similarity',rotation_x=30)
