Summary
Natural language processing (NLP) is a massive field of study that use statistics and computers to apply prediction for example for topic identification, text classification, chatbots, translation and sentiment analysis and so forth. This notebook presents word processing including tokenization, stemming, lemmatization, work frequency, named entity recognition (NER) and how to apply NLP supervised learning to detect fake/real news.
Python functions and data files needed to run this notebook are available via this like.
#nltk.download()
import pandas as pd
pd.set_option('display.max_columns', None)
import numpy as np
import nltk
import warnings
warnings.filterwarnings('ignore')
from IPython.display import HTML
from functions import* # import require functions to run this notebook
Regular Expression¶
Regular expression are strings that can be used for special syntax which allow to find pattern and trend in other strings. For example, it can be applied to find all web links in a document or parse email addresses; moreover, removing unwanted characters.
Python re library has many application for regular expression. Match a pattern in string can be find by match:
re.match(pattern, string)
import re
re.match ('ert', 'ert898')
# \w+ is to find the first word it sounds
re.match ('\w+', 'hey mehdi')
There are many characters and patterns can be learned and memorized by regular expression from re library including split, findall,match (only match), search (search for entire string)... below shows common regex patterns with groups (| OR, () define a group, []define explicit character ranges)
| pattern | matches | example |
|---|---|---|
| \d+ | digit | 8 |
| \s | space | '' |
| \w+ | word | 'last' |
| + or * | greedy match | 'yyyyyyy' |
| .* | wildcard | 'username89' |
| [a-z] | lowercase | 'hbalepof' |
| \S | not space | 'no_spaces' |
| (a-z) | a, - and z | 'a-z' |
| [A-Za-z]+ | upper and lowercase English alphabet | 'ITNFPafrets' |
| [A-Za-z-.]+ | upper and lowercase English alphabet, - and . | 'mehdirezvandehy.com' |
| [0-9] | numbers from 0 to 9 | 7 |
| (\s+l,) | spaces or a comma | ', ' |
s = ('(\d+|\w+)')
re.findall(s, 'He now has 5 snakes.')
str_ = 'match lowercase spaces nums like 12, but no commas'
re.match('[a-z0-9 ]+', str_)
See re — Regular expression operations for more information.
Tokenization¶
The first step of NLP is to separate a corpus into documents and a document into words. This process is called tokenization because the resulting tokens contain words and punctuations. While splitting a corpus into documents, documents into sentences, and sentences into words sounds trivial, with a bit of regular expression (RegEx), there are many non-trivial language-specific issues. Think about the different uses of periods, commas, and quotes and think about whether you would have thought about the following words in English: don't, Mr. Smith, Johann S. Bach, and so on. The Natural Language Toolkit (nltk) Python package provides implementations and pre-trained transformers for many NLP algorithms, as well as for word tokenization.
document="Almost before we knew it, we had left the ground. The unknown holds its grounds."
#Tokenization
from nltk.tokenize import word_tokenize
tokens = word_tokenize(document)
tokens
Other nltk tokenizers are as below:
sent_tokenize¶
It tokenizes a document into sentences:
from nltk.tokenize import sent_tokenize
sent_tokenize(document)
regexp_tokenize¶
It tokenizes a string or document based on a regular expression pattern:
from nltk.tokenize import regexp_tokenize
s = "Good muffins cost $3.88\nin New York. Please buy me\ntwo of them.\n\nThanks."
regexp_tokenize(s, pattern='\w+|\$[\d\.]+|\S+')
TweetTokenizer¶
Usually used for tweet tokenization, which allows to separate hashtags, mentions and lots of exclamation points:
from nltk.tokenize import TweetTokenizer
tt = TweetTokenizer()
tweet = "This is a cooool #dummysmiley: :-) :-P <3 and some arrows < > -> <-- @remy: This is waaaaayyyy too much for you!!!!!!"
print(tt.tokenize(tweet))
Histogram for Length of Words¶
doc='May name is Mehdi and I am a Data Scientist'
tokens = word_tokenize(doc)
tokens_len = [len(itok) for itok in tokens]
import matplotlib.pyplot as plt
font = {'size' : 11}
plt.rc('font', **font)
fig, ax1 = plt.subplots(figsize=(9, 8), dpi= 130, facecolor='w', edgecolor='k')
clmns=tokens
ax1=plt.subplot(2,1,1)
ax1.bar(clmns, tokens_len, width=0.2,lw = 0.6, align='center', ecolor='black',
edgecolor='k',capsize=.9,color='b')
plt.title('Histogram of Word Length',fontsize=15)
plt.ylabel('Length',fontsize=12)
ax1.set_xticklabels(clmns, rotation=90,y=0.02)
ax1.grid(linewidth=0.1)
plt.show()

Bag of Words (BOW)¶
It only counts the words in document after tokenization. The more frequent a word is, the more importance it could have in a text. Based on the number of words used in a text, significant words can be defined
from nltk.tokenize import word_tokenize
from collections import Counter
words="Almost before we knew it, we had left the ground. The unknown holds its grounds."
tokens=word_tokenize(words)
Counter(tokens)
As you can see, data processing should be applied before using BOW
Stop words¶
In the preceding code, we used the word.islanum() function to extract only alphanumeric tokens and make them all lowercase. The preceding list of words already looks much better than the initial naive model. However, it still contains a lot of unnecessary words, such as the, we, had, and so on, which don't convey any information.
In order to filter out the noise for a specific language, it makes sense to remove these words that appear often in texts and don't add any semantic meaning to the text. It is common practice to remove these so-called stop words using a pre-trained look-up dictionary. You can load and use such a dictionary by using the pre-trained nltk library in Python:
# Remove punctuation
words = [word.lower() for word in tokens if word.isalnum()]
words
#Stop words
from nltk.corpus import stopwords
nltk.download('stopwords')
stopword_set = set(stopwords.words('english'))
words = [word for word in words if word not in stopword_set]
words
Stemming¶
Removing the affixes of words to obtain the stem of a word is also called stemming. Stemming refers to a rule-based (heuristic) approach to transform each occurrence of a word into its word stem. Here is a simple example of some expected transformations: cars -> car
words = stem(words)
words
Lemmatization¶
When looking at the stemming examples, we can already see the limitations of the approach. What would happen, for example, with irregular verb conjugations—such as are, am, or is—that should all be normalized to the same word, be? This is exactly what lemmatization tries to solve using a pre-trained set of vocabulary and conversion rules, called lemmas. The lemmas are stored in a look-up dictionary and look similar to the following transformations:
are -> be
is -> be
taught -> teach
better -> good
There is one very important point to make when speaking about lemmatization. Each lemma needs to be applied to the correct word type, hence a lemma for nouns, verbs, adjectives, and so on. The reason for this is that a word can be either a noun or a verb in the past tense. In our example, ground could come from the noun ground or the verb grind; left could be an adjective or the past tense of leave. So, we also need to extract the word type from the word in a sentence—this process is called Point of Speech (POS) tagging.
Luckily, the nltk library has us covered once again. To estimate the correct POS tag, we also need to provide the punctuation:
words_pos = categorize(words)
words = set(lemmatize(words, words_pos))
words
More accurate BOW is:
Counter(words)
Gensim is popular open source NLP package. It used top academic models to apply complex tasks including topic identification and document comparison.
Word Vector¶
A word vector is an attempt to mathematically represent the meaning of a word. In essence, a computer goes through some text (ideally a lot of text) and calculates how often words show up next to each other. These frequencies are represented with numbers.
For example in Figure below, king - queen is equal man - women, Germany to Berlin as China to Beijing. Deep learning algorithms are used to create word vectors and has been able to achieve this meaning based on how much those words are used through the text

Image retrieved from https://developers.google.com/machine-learning/crash-course/embeddings/translating-to-a-lower-dimensional-space
Gensim allows you to make a corpora and dictionary with simple classes and function. Corpse or plural as corpora set up texts used to apply Natural Language Processing
from gensim.corpora.dictionary import Dictionary
from nltk.tokenize import word_tokenize
documents = ['I was going to say something awesome, but I simply cant because the movie is so bad.',
'I really liked the movie!',
'More space films, please!',
"This movie is bad, do not love it at all",
"It might have bad actors, but everything else is good.",
"I love this movie"]
First we need to do basic preprocessing:
# Tokenization
tokens = [word_tokenize(doc.lower()) for doc in documents]
# Remove punctuation
tokens = [[word for word in tokens_ if word.isalnum()] for tokens_ in tokens]
# Stop words
words = [[word for word in tokens_ if word not in stopword_set] for tokens_ in tokens ]
#
# Lemmatization
words_pos = [categorize(words_) for words_ in words ]
words = [set(lemmatize(words_, words_pos_)) for words_, words_pos_ in zip(words,words_pos) ]
Then we can pass cleaned tokenized document to gensim dictionary class. This creates mapping with id for each token. The corpse has begun. We can present whole document with a list of token id (numbers) and how often this token will appear in document
dictionary = Dictionary(words)
dictionary.token2id
with the dictionary, we can generate a gensim corpse, this different than normal corpse which only a collection of documents. gensim applies a simple bag of words model which transform each document into bag of words using token ids and frequency of each token in document. Each document is now a series of tuples, first item is token id from dictionary and second item represents token frequency in document. The new bag of words is converted to corpse by gensim. Unlike other model, this gensim model can be easily saved to reused. We can update the dictionary with new text and can be used for more advanced and feature rich bag-of-words.
# This is a gensim corpse
corpus = [dictionary.doc2bow(doc) for doc in words]
corpus
TF-idf with gensim¶
TF-idf stands for Term Frequency - Inverse Document Frequency. It is a commonly used NLP model that helps to determine the most important words in each document in the corpus. The idea for this approach is each corpus may have shared words beyond just stopwords; the importance of those words should be degraded or give lower weight.
TF-idf makes sure that most common words does not represent as key words. It gives high weight to document specific words and make common words shows over the entire corpse lower weight.
The term frequency (ft) counts all the terms in a document. The inverse document frequency (idf) is computed by dividing the total number of documents (N) by the counts of a term in all documents (fd). The idf term is usually log-transformed as the total count of a term across all documents can get quite large.
Term frequency-inverse document frequency weight is calculated by:
$\large \omega_{i,j}=tf_{i,j}.log(\frac{N}{df_{i}})$
$\omega_{i,j}$ → weight of term $i$ in document $j$
$tf_{i,j}$ → term frequency (number of occurrences) of term $i$ in document $j$
$N$ → number of documents in the corpus
$df_{i}$ → number of documents containing term $i$
See this page for more information.
from gensim.models.tfidfmodel import TfidfModel
tfidf = TfidfModel(corpus)
tfidf[corpus[1]]
# More clear print
for doc in tfidf[corpus]:
print([[dictionary[id], np.around(freq,decimals=2)] for id, freq in doc])
NER (Named Entity Recognition)¶
NER is an important NLP task used to distinguish named entities in the text including places, organization, people, dates, states, etc)
It can also be used for topic identification to answer the questions of Who? When? What? See the example below:

Retrieved from medium
There are a number of excellent open-source libraries that we can apply NER including NLTK, SpaCy and Stanford NER CoreNLP, which is integrated into Python by NLTK.
First we apply NER with NLTK. See example below that tags each verb, none, adjectives based on English grammar
import nltk
sentence = '''My friend Ali told me that Calgary is very cold although it is selected as the most cleanest city in the world.'''
tokenized = nltk.word_tokenize(sentence)
tagged = nltk.pos_tag(tokenized)
tagged
Then we pass this tag sentence into a chunk function (name entity chunk). This return sentences as trees which has leaves and sub trees representing more complex grammar
nltk.download('maxent_ne_chunker')
nltk.download('words')
print(nltk.ne_chunk(tagged))
Here are the meaning for abbreviation tags:
| Abbreviation | Meaning |
|---|---|
| CC | coordinating conjunction |
| CD | cardinal digit |
| DT | determiner |
| EX | existential there |
| FW | foreign word |
| IN | preposition/subordinating conjunction |
| JJ | This NLTK POS Tag is an adjective (large) |
| JJR | adjective, comparative (larger) |
| JJS | adjective, superlative (largest) |
| LS | list market |
| MD | modal (could, will) |
| NN | noun, singular (cat, tree) |
| NNS | noun plural (desks) |
| NNP | proper noun, singular (sarah) |
| NNPS | proper noun, plural (indians or americans) |
| PDT | predeterminer (all, both, half) |
| POS | possessive ending (parent\ ‘s) |
| PRP | personal pronoun (hers, herself, him, himself) |
| PRP$ | possessive pronoun (her, his, mine, my, our ) |
| RB | adverb (occasionally, swiftly) |
| RBR | adverb, comparative (greater) |
| RBS | adverb, superlative (biggest) |
| RP | particle (about) |
| TO | infinite marker (to) |
| UH | interjection (goodbye) |
| VB | verb (ask) |
| VBG | verb gerund (judging) |
| VBD | verb past tense (pleaded) |
| VBN | verb past participle (reunified) |
| VBP | verb, present tense not 3rd person singular(wrap) |
| VBZ | verb, present tense with 3rd person singular (bases) |
| WDT | wh-determiner (that, what) |
| WP | wh- pronoun (who) |
| WRB | wh- adverb (how) |
SpaCy is another NLP library similar to gensim to apply NER but with different implementations. It focus on generating NLP pipelines to create models and corpora
import spacy
from spacy import displacy
#import en_core_web_sm
NER = spacy.load('en_core_web_sm')
sentence = '''My friend Ali told me that Calgary is very cold although it is selected as the most cleanest city in the world.'''
text1=NER(sentence)
for word in text1.ents:
print(word.text, word.label_)
spacy.explain("GPE")
displacy.render(text1, style="ent", jupyter=True)
The example above is on entity level in the following example, we are demonstrating token-level entity annotation using the BILUO tagging scheme to describe the entity boundaries
print([(X, X.ent_iob_, X.ent_type_) for X in text1])
"O" means it is outside an entity, "B" means the token begins an entity, "I" means it is inside an entity, and "" means no entity tag is set.
Lets get more serious about this. Load the Internet Movie DataBase (IMDB) reviews data set. This example is based on a TensorFlow example that you can find here.
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
train_data, test_data = tfds.load(name="imdb_reviews",
split=["train", "test"],
batch_size=-1, as_supervised=True)
train_examples, train_labels = tfds.as_numpy(train_data)
i=150
text2=train_examples[i].decode("utf-8")
text2
text2=NER(text2)
displacy.render(text2, style="ent", jupyter=True)
There are several reasons to SpaCy for NER:
- Pipelines can be easily created
- Compared with
nltk, it has different entity types
- It can easily find informal language corpora such as entities from Tweets, facebook, etc
- It is growing quickly
Multilingual by Polyglot¶
Plolyglot is another NLP library which uses word vectors for simple tasks such as NER. Why we need Plolyglot: the main reason we can use vectors for many different languages (has more than 130 languages). So, transliteration (mapping from one system of writing to another) can be applied.
We do not need to tell Polyglot which language we are using:
## pip install polyglot==14.11
#
#from polyglot.text import Text
#ext = """ رئیس جمهور با ابراز خرسندی از روابط بسیار خوب ایجاد شده میان شرکتهای تجاری ایران و مالزی اظهار داشت: موضوعات مختلفی در جهت توسعه همکاریهای دوجانبه وجود دارد که امیدوارم در سایه تعامل و تلاشهای مقامات دو کشور شاهد تحقق آنها باشیم.."""
#
#ptext = Text(ext)
#ptext.entities
NLP Supervised Learning¶
The steps are :
- Process data including............
- Find label (e.g. positive or negative, Fake or Real)
- Split data into training and test sets
- Extract features from text to use them to predict label
- Using
scikit-leanwith bag-of-words vectors
- Using
- Evaluate trained model with test set.
import pandas as pd
# Read data set
data_news=pd.read_csv('./Data/fake_or_real_news.csv')
data_news
# select a corpus of only four documents
corpus = data_news['title'].iloc[:4].values.tolist()
corpus
# Vectorize of four documents using CountVectorizer
count,df,model=CountVectorizer_train(corpus)
df
# Vectorize of four documents using TfidfVectorizer
pd.set_option('display.max_columns', None)
count,df,model=CountVectorizer_train(corpus,Tfidf=True)
df
For this notebook, we consider some predictive models to predict if a text is fake or real. Metrics such as accuracy, sensitivity... with confusion matrix and area under the curve (AUC) to evaluate the performance.
Data Processing¶
The example above shows how to prepare training set for NLP supervised learning. Now we can do apply prediction:
data_news
# Divid data into training set and test set
from sklearn.model_selection import train_test_split
y=np.where(data_news['label']=='REAL',1,0)
X_train, X_test, y_train, y_test = train_test_split(data_news['text'].tolist(), y,test_size=0.33,random_state=43)
# Vectorize training set with TfidfVectorizer
X_train_processed,model_trained=CountVectorizer_train(X_train, Tfidf=True, counts=False)
X_train_processed
# Vectorize test set with TfidfVectorizer
X_test_processed=CountVectorizer_test(X_test, model=model_trained, Tfidf=True, counts=False)
X_test_processed
predictor_name= ['Dummy Classifier', 'Naive Bayes', 'Logistic Regression', 'Random Forest']
n_algorithm=len(predictor_name)
# Metrics
Accuracy = n_algorithm*[0]
Precision = n_algorithm*[0]
Sensitivity = n_algorithm*[0]
Specificity = n_algorithm*[0]
#
prediction_prob=n_algorithm*[0]
ir=0
# Train Model
predictor = DummyClassifier(strategy="stratified",random_state=12)
predictor.fit(X_train_processed, y_train)
# prediction with cross validation
prediction_prob[ir]=predictor.predict_proba(X_test_processed)
Performance Measurement¶
The most common approach for assessment of classification is accuracy, which is calculated by number of true predicted over total number of data. However, accuracy alone may not be practical for performance measurement of classifiers, especially in cease of skewed datasets. Accuracy should be considered along with other metrics. Confusion matrix is a much better way to evaluate the performance of a classifier. The general idea is to consider the number of times instances of negative class are misclassified as positive class and vice versa. Three more metrics Sensitivity, Precision and Specificity can be calculated as well as Accuracy:
Accuracy=(𝑇𝑃+𝑇𝑁)/(𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁): Accuracy is simply the fraction of the total samples that is correctly identified.
Sensitivity (Recall)= 𝑇𝑃/(𝑇𝑃+𝐹𝑁): Sensitivity is the proportion of correct positive predictions to the total positive classes.
Precision= 𝑇𝑃/(𝑇𝑃+𝐹𝑃): Precision is the proportion of correct positive prediction to the total predicted values.
Specificity= 𝑇𝑁/(𝑇𝑁+𝐹𝑃) Specificity is the true negative rate or the proportion of negatives that are correctly identified.
TP: True Positives, FP: False Positives, FN: False Negatives, TN: True Negatives
Another common approach to measure performance is the receiver operating characteristic (ROC). The ROC curve plots the true positive rate (Sensitivity) against the false positive rate (1-Specificity). Every point on the ROC curve represents a chosen cut-off even though it cannot be seen. For more information and details see ROC. The most common way to compare classifiers is to measure the area under the curve (AUC). A perfect classifier will have a ROC AUC equal to 1, whereas a purely random classifier will have a ROC AUC equal to 0.5 (See Figure below).
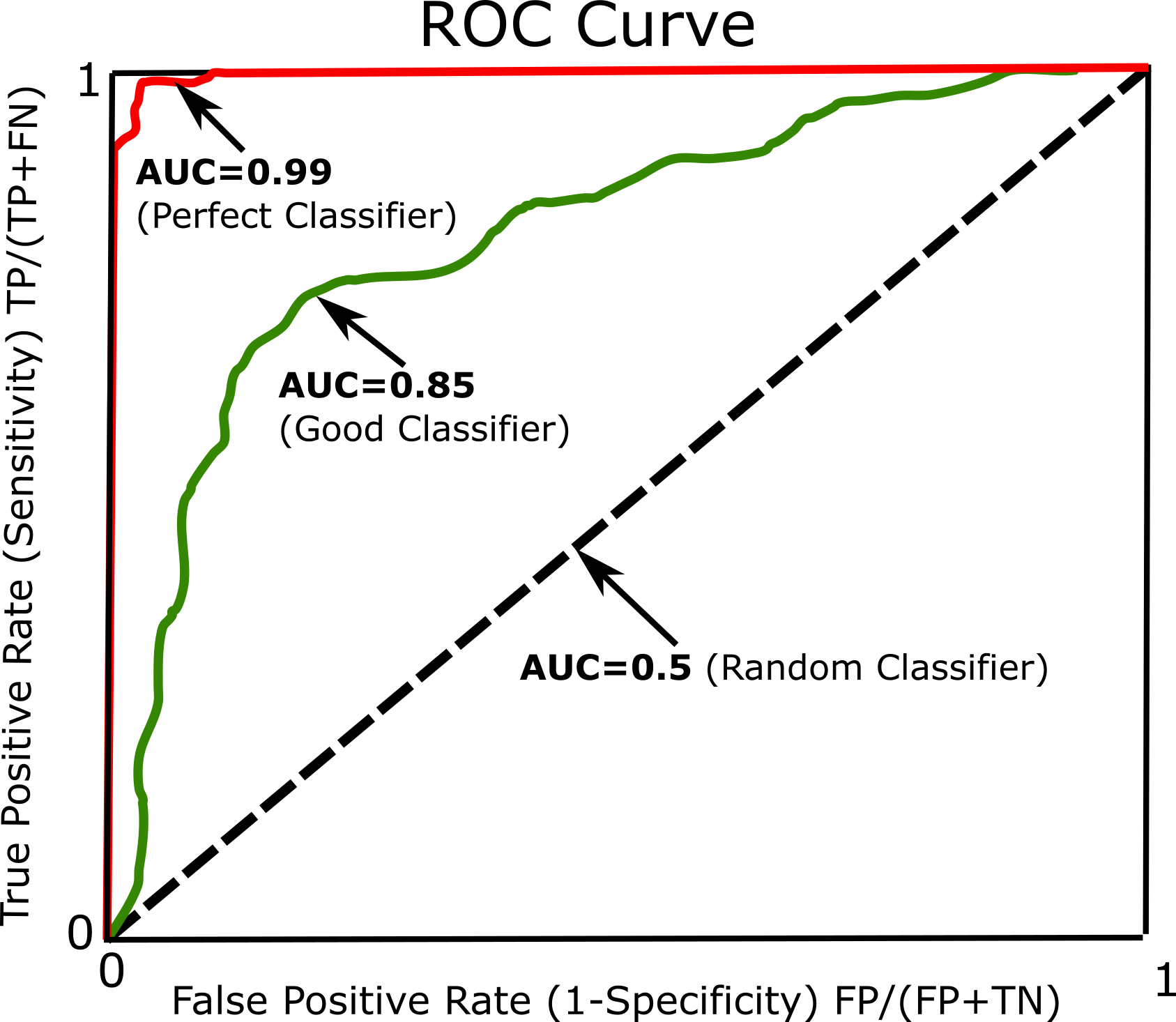
Naive Bayes¶
Naive Bayes model is commonly used for testing NLP classification problems because of basis in probability. It answers the probability of outcome given a particular piece of data. Naive Bayes is not the best tools for a job but it is simple and effective.
ir=1
predictor = MultinomialNB()
predictor.fit(X_train_processed, y_train)
prediction_prob[ir] = predictor.predict_proba(X_test_processed)
font = {'size' : 6}
plt.rc('font', **font)
fig = plt.subplots(figsize=(5, 5), dpi= 250, facecolor='w', edgecolor='k')
ax1=plt.subplot(1,2,1)
Accuracy[ir], Precision[ir], Sensitivity[ir], Specificity[ir]=Conf_Matrix(y_test,
prediction_prob[ir],label=['Fake','Real'], axt=ax1,t_fontsize=6,x_fontsize=6,y_fontsize=6,
title='Naive Bayes')

Logistic Regression¶
ir=2
predictor = LogisticRegression(random_state=42)
predictor.fit(X_train_processed, y_train)
prediction_prob[ir] = predictor.predict_proba(X_test_processed)
font = {'size' : 6}
plt.rc('font', **font)
fig = plt.subplots(figsize=(5, 5), dpi= 250, facecolor='w', edgecolor='k')
ax1=plt.subplot(1,2,1)
Accuracy[ir], Precision[ir], Sensitivity[ir], Specificity[ir]=Conf_Matrix(y_test,
prediction_prob[ir],label=['Fake','Real'], axt=ax1,t_fontsize=6,x_fontsize=6,y_fontsize=6,
title='Logistic Regression')

Random Forest¶
ir=3
predictor = RandomForestClassifier(random_state=42)
predictor.fit(X_train_processed, y_train)
prediction_prob[ir] = predictor.predict_proba(X_test_processed)
font = {'size' : 6}
plt.rc('font', **font)
fig = plt.subplots(figsize=(5, 5), dpi= 250, facecolor='w', edgecolor='k')
ax1=plt.subplot(1,2,1)
Accuracy[ir], Precision[ir], Sensitivity[ir], Specificity[ir]=Conf_Matrix(y_test,
prediction_prob[ir],label=['Fake','Real'], axt=ax1,t_fontsize=6,x_fontsize=6,y_fontsize=6,
title='Random Forest')

Area Under the Curve (AUC)¶
prediction_prob
font = {'size' : 12}
plt.rc('font', **font)
fig,ax = plt.subplots(figsize=(6.5,6), dpi= 100, facecolor='w', edgecolor='k')
AUC(prediction_prob,np.array(y_test), n_algorithm=4, linewidth=3, label=predictor_name
,title='Receiver Operating Characteristic (ROC)')
