ENPE 519.11/ENCH 619.78 Machine Learning – Energy Systems at University of Calgary¶
- Instructor: Mehdi Rezvandehy
Pandas Introduction¶
Pandas is an open source Python package for data manipulation and analysis with high-performance and easy-to-use methods. It is based on the dataframe concept in the R programming language. Pandas can be used as the primary tools for data processing, data manipulation and data cleaning.
We will use a dataset for oil production of 1000 hydrocarbon wells in Alberta (WPD.csv). The target is oil production prediction using well properties including location, depth, deviation, porosity, permeability and so on. The well properties are retrieved from geoSCOUT; but location of the wells are changed and some key properties are manipulated for confidentially reason and for not being used for other reasons. This data is retrieved and generated for this course to learn data processing and apply Machine Learning. The prediction should NOT be used for any Publication because the original data is modified data.
Look at Data¶
# Reading data in Pandas
import pandas as pd # import Pandas
df = pd.read_csv("WPD.csv") # Read data file
#df.head()
df[0:5] # Display data
The columns function gives the name of the columns in your data file.
column=list(df.columns)
print(column)
The info() function gives some information about the data type: string float or null (missing values).
df.info()
df
The describe function gives some statistical analysis for each column if the data type is not string.
df.describe()
Data Cleaning¶
Missing (NaN) Values¶
It is ideal to have valid value for every rows and columns. In reality, missing values is one of the main challenges faced by machine learning. There are some approaches in practice to deal with missing values.
Option 1: Drop Column
One naive approach is to remove columns that have missing values with drop() function.
Select_column=column[3:8] # Select columns that have missing
Select_column
df_drop_c=df.copy() # Copy to avoid modifying the original data
df_drop_c.drop(Select_column,axis=1, inplace=True) # Drop selected 5 columns
df_drop_c
aa=df_drop_c.drop(1,axis=0)
aa
df_drop_c
df_drop_c.info()
This approach is not reliable since the information of 5 columns without missing values have been removed from data set.
Option 2: Drop Row
Another approach is to remove rows that have missing values with dropna() function.
df_drop_=df.copy() # Copy to avoid modifying the original data
df_drop_r=df_drop_.dropna() # Drop rows with missing values
df_drop_r
df_drop_r.info()
This approach is also not recommend because number of data (rows) have decreased from 1000 to 426.
Option 3: Replace with Median (mean)
A common practice is to replace missing values with the median (mean) value for that column. The median is the middle value of a list that 50% are less and 50% are bigger. See Median. The following code replaces all missing values in 5 columns with the median value of each column values.
df_im=df.copy()
# Get the median of each variable and replace the missing values with median
for i in range(len(Select_column)):
P50 = df[Select_column[i]].median() # Calculate median of each column
df_im[Select_column[i]] = df_im[Select_column[i]].fillna(P50) # replace NaN with median(P50)
df_im
df_im.info()
Remove Outliers¶
Outliers are usually extreme high or low values that are different from pattern of majority data. Outliers should be removed from dataset (we should be careful not to consider novelty as outlier). A straightforward approach to detect outliers are several (n) standard deviations from the mean $m\pm n\sigma$ ($m$=mean, $\sigma$=standard deviation). For example, an outlier can bigger than $m+ 3\sigma $ or less than can bigger than $m- 3\sigma $. The following function can be used to apply this approach.
def outlier_remove(df, n,name):
"""Delete rows for a specified column where values are out of +/- n*sd standard deviations
df : Pandas dataframe
n : n in the equation 𝑚±𝑛𝜎
name: Column name
"""
mean=df[name].mean() # Calclute mean of column
sd=df[name].std() # Calclute standard deviation of column
drop_r = df.index[(mean -n * sd> df[name]) | (mean+n * sd< df[name])] # Find data that are not within 𝑚±𝑛𝜎
df.drop(drop_r, axis=0, inplace=True) # Drop data
df.reset_index(inplace=True, drop=True) # Reset index
# Drop outliers in last column 'OIL Prod. (e3m3/month)'
df_im_out=df_im.copy()
outlier_remove(df_im_out,n=3,name='OIL Prod. (e3m3/month)')
df_im_out
Concatenation¶
A new data frames can be built by concatenating rows and columns. A new dataframe is created by concatenating two columns together 'Measured Depth (m)' and 'OIL Prod. (e3m3/month)' using the concat() function.
col_1= df_im['Measured Depth (m)']
col_2 = df_im['OIL Prod. (e3m3/month)']
result = pd.concat([col_1, col_2], axis=1)
result
Two rows can be concatenated together using concat() function. The code below concatenates the first 4 rows and the last 3 rows of the previous dataset after imputation.
row_1= df_im[0:4] # Retrieve first 4 rows
row_2 = df_im[-4:-1] # Retrieve last 3 rows
result = pd.concat([row_1, row_2], axis=0) # Concatenate rows
result
Saving a Dataframe as CSV¶
You can simply save a dataframe as CSV by the following code. The following code performs a shuffle and then saves a new copy.
filename="myfile.csv"
df_im.to_csv(filename, index=False) # index = False not writing row numbers
Shuffling, Grouping and Sorting¶
Shuffling Dataset
An example of shuffling is playing the game of cards. All the cards are collected at the end of each round of play, shuffled to ensure that cards are distributed randomly and each player receives cards based on chance. In Machine Learning, the data set should be split into training and validation datasets. So, shuffling is very important to avoid any element of bias/patterns in the split datasets.
If consistent shuffling of the data set is required for several times of running the code, a random seed can be used. See code below.
import numpy as np
#np.random.seed(82)
df_shfl = df_im.reindex(np.random.permutation(df.index))
df_shfl.reset_index(inplace=True, drop=True) # Reset index
df_shfl[0:5]
Grouping Data Set
Grouping is applied to summarize data. The following codes performs grouping; generating the mean and sum of each category for feature 'Prod. Formation' in target variable 'OIL Prod. (e3m3/month)'.
gb_mean=df_im.groupby('Prod. Formation')['OIL Prod. (e3m3/month)'].mean()
gb_mean
gb_sum=df_im.groupby('Prod. Formation')['OIL Prod. (e3m3/month)'].sum()
gb_sum
Sorting Data Set
df_sort = df_im.sort_values(by='Measured Depth (m)', ascending=True)
#df_sort.reset_index(inplace=True, drop=True) # Reset index
df_sort
Feature Engineering¶
Feature engineering is the process of extracting new feature from raw data via data mining techniques. The new features can be used to enhance the performance of machine learning algorithms. New features could also be calculated from the other fields. For the data set WPD.csv, we can add "Surface-Casing Weight (kg/m)" and "Production-Casing Weight (kg/m)" as a new data set.
df_im_c=df_im.copy()
df_im.insert(1, 'New Column', (df_im['Surface-Casing Weight (kg/m)']*df_im['Production-Casing Weight (kg/m)']).astype(int))
df_im
Standardize (Normalize) Values¶
Most Machine Learning algorithms require to standardize the input to have a reliable comparison between two values of different variables. For example, if you have variable one with a range of 3 to 1000 and variable two with range 1 to 3; we cannot have a good comparison since the highest value of variable two (3) is the lowest value in variable two. This inconsistency in data values leads to low performance in Machine Learning algorithms. So, it is highly recommended to standardize (normalize) your data to have the same the mean($\mu$) and the standard deviation ($\sigma$) before feeding Machine Learning algorithms. One very common Machine learning standardization (normalization) is the Z-Score:
$\Large z = \frac{x - \mu}{\sigma} $
where $ \mu = \frac{1}{n} \sum_{i=1}^n x_i$, $\sigma = \sqrt{\frac{1}{n} \sum_{i=1}^n (x_i - \mu)^2}$, $n$ is number of data. This ensures that each variable have $\mu=0$ and $\sigma=1$
This standardization should be applied for all features except the target (label). For WPD.csv data set, the target is "OIL Prod. (e3m3/month)" that should not be changed.
The following Python code replaces the 'Measured Depth (m)' with a z-score. This can be done for all variables.
from scipy.stats import zscore
mean=df_im['Measured Depth (m)'].mean()
variance=df_im['Measured Depth (m)'].var()
print("Before standardization: Mean= ",int(mean), ", variance= ",int(variance))
df_im['Measured Depth (m)'] = zscore(df_im['Measured Depth (m)'])
mean=df_im['Measured Depth (m)'].mean()
variance=df_im['Measured Depth (m)'].var()
print("After standardization: Mean= ",int(mean), ", variance= ",int(variance))
df_im[0:5]
Categorical Values¶
The input data for Machine Learning should be completely numeric which means any text should be converted to number. In the data set WPD.csv, the columns 'Deviation (True/False)' and 'Prod. Formation' have categorical values. Use value_counts() function to find out what categories exist and how many data belong to each category.
df_c=df_im.copy()
df_c['Deviation (True/False)'].value_counts()
df_c['Prod. Formation'].value_counts()
We can replace each test with numbers starting from 0
df_c['Deviation (True/False)']=df_c['Deviation (True/False)'].replace(False, 0) # Replace False with 0
df_c['Deviation (True/False)']=df_c['Deviation (True/False)'].replace(True, 1) # Replace True with 1
df_c[0:5]
df_c['Prod. Formation']=df_c['Prod. Formation'].replace('Shale', 0) # Replace Shale with 0
df_c['Prod. Formation']=df_c['Prod. Formation'].replace('Sand', 1) # Replace Sand with 1
df_c['Prod. Formation']=df_c['Prod. Formation'].replace('Shale-Sand', 2) # Replace Shale-Sand with 2
df_c[0:5]
One challenge with this representation is that Machine Learning algorithms consider two nearby values are more similar than two distant values. This may be fine for some cases (order of categories “bad”, “average”, “good”), but this is not always true. A common solution is to have one binary attribute per category. This is called one-hot encoding, because we only have one attribute equal to 1 (hot), while the others are 0 (cold).
One_hot = pd.get_dummies(['a','b'],prefix='Deviation')
print(One_hot)
These dummies should be merged back into the data frame.
One_hot = pd.get_dummies(df_im['Deviation (True/False)'],prefix='Deviation')
print(One_hot[0:10]) # Just show the first 10
df_one_hot = pd.concat([df_im,One_hot],axis=1)
df_one_hot[0:5]
This should be done for 'Prod. Formation' column.
One_hot = pd.get_dummies(df_im['Prod. Formation'],prefix='Formation')
df_one_hot = pd.concat([df_one_hot,One_hot],axis=1)
df_one_hot[0:5]
Finally, the original columns 'Deviation (True/False)' and 'Prod. Formation' should be removed.
df_one_hot.drop(['Deviation (True/False)','Prod. Formation'], axis=1, inplace=True)
#df_one_hot
Split Data to Training and Validation¶
Machine Learning models should be evaluated based on prediction for never-before-seen data set. The models usually have high performance for the data that are trained by. However, the main aim of training is to have high performance on completely new data set. So, data are split into training and validation set. The machine learning models learn from the training data, but based on the validation data are evaluated: the data should be divided into training and validation set according to some ratio. The common ratios are 80% training and 20% validation. The image below shows how a model is trained on 80% of the data and then validated against the remaining 20%. Based on feedback performance on evaluation set, Machine learning algorithms are modified. This process is repeated until the model's performance is satisfied. This repetition also could lead to information leak. The model could perform well on the validation set but not on a new data set. So, sometimes, a portion of data are hold-out for testing. We will talk about this on the next lectures
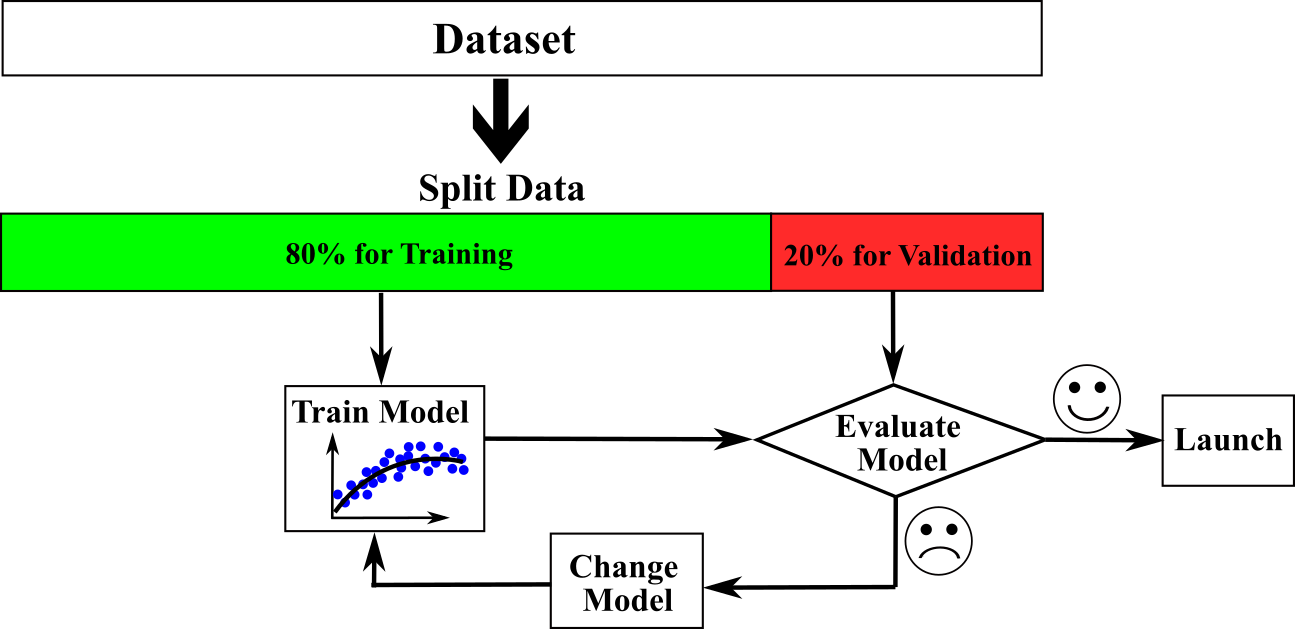
The following code splits the data into 80% training and 20% validation set.
import numpy as np
df = df.reindex(np.random.permutation(df.index)) # Shuffle the data
df.reset_index(inplace=True, drop=True) # Reset index
MASK = np.random.rand(len(df)) < 0.8
df_train = pd.DataFrame(df[MASK])
df_validation = pd.DataFrame(df[~MASK])
print("Number of Training: "+ str(len(df_train)))
print("Number of Validation: "+ str(len(df_validation)))